1、XML概念
一个完整的XML文件:
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>- xml概念:
XML指可扩展标记语言(Extensible Markup Language);
XML是一种标记语言,很类似HTML;
XML的设计宗旨是传输数据,而非显示数据;
XML标签没有被预定义,您需要自行定义标签;
XML被设计为具有自我描述性;
XML是W3C的推荐标准
- xml特点:
XML是SGML的简化版本
XML提示了数据本身的意义
XML是可扩展的
XML是跨平台的
XML是结构化的
XML是基于文本的
XML的数据与其显示格式是分离的
XML文档比HTML文档更容易访问
XML是一种树形存储结构
- xml与HTML的差异:
XML不是HTML的替代。XML和HTML为不同的目的而设计:
XML被设计为传输和存储数据,其焦点是数据的内容;
HTML被设计用来显示数据,其焦点是数据的外观;
HTML旨在显示信息,而XML旨在传输信息。
HTML是一个大小写不敏感的,XML是大小写敏感的。
HTML有着固定的显示标准,XML显示是依赖应用灵活定义
- xml应用场景
作为系统或应用的配置文件使用,如tomcat中的web.xml
作为应用程序的数据存储文件或日志存储文件
数据库的功能之一,支持XML存储
WebService协议用语言,soap协议
IM通信协议标准,如XMPP协议
部分矢量图像存储格式,如果SVG图片
部分流媒体协议,如果CML
2、XML语法
所有XML元素都须有关闭标签 ,而不像部分的HTML标签
声明语句也可以不要
XML 标签对大小写敏感
必须正确嵌套
文档必须有根元素
属性值须加引号
转义字符
PCDATA 是会被解析器解析的文本。这些文本将被解析器检查实体以及标记
CDATA 是不会被解析器解析的文本
元数据(有关数据的数据)应当存储为属性,而数据本身应当存储为元素。
3、XML解析方式
两种方式:SAX,DOM
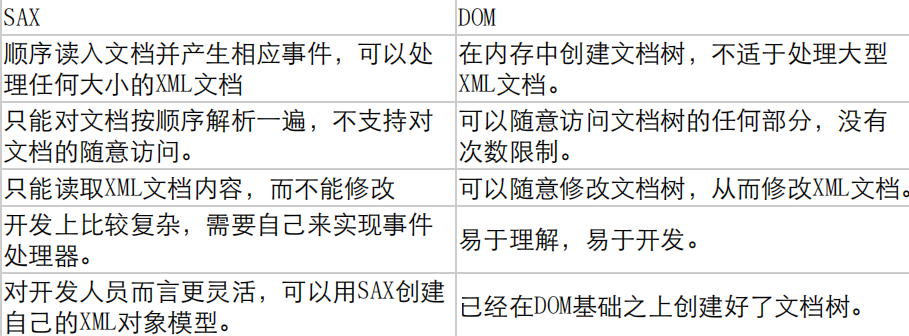
SAX适于处理下面的问题:
- 对大型文档进行处理。
- 只需要文档的部分内容,或者只需要从文档中得到特定信息。
- 想创建自己的对象模型的时候。
DOM适于处理下面的问题:
需要对文档进行修改
需要随机对文档进行访问,例如XSLT解析器。
需要校验XML的合法性,完整性
4、Java解析XML
- DOM解析器
由W3C提供的接口,它将整个XML文档读入内存,构建一个DOM树来对各个节点(Node)进行操作。(参见代码)
- SAX解析器
SAX不用将整个文档加载到内存,基于事件驱动的API(Observer模式),用户只需要注册自己感兴趣的事件即可。SAX提供EntityResolver, DTDHandler, ContentHandler, ErrorHandler接口,分别用于监听解析实体 事件、DTD处理事件、正文处理事件和处理出错事件,与AWT类似, SAX还提供了一个对这4个接口默认的类DefaultHandler(这里的默认实 现,其实就是一个空方法),一般只要继承DefaultHandler,重写自己感兴趣的事件即可。
- JDOM解析器
JDOM与DOM非常类似,它是处理XML的纯JAVA API,API大量使用了Collections类,且JDOM仅使用具体类而不使用接口。 JDOM 它自身不包含解析器。它通常使用 SAX2 解析器来解析和验证输入 XML 文档 (尽管它还可以将以前构造的 DOM 表示作为输入)。它包含一些转换器以将 JDOM 表示输出成 SAX2 事件流、DOM 模型或 XML 文本文档
- DOM4J解析器
DOM4J是目前在xml解析方面是最优秀的(Hibernate、Sun的 JAXM也都使用dom4j来解析XML),它合并了许多超出基本 XML 文档表示的功能,包括集成的 XPath 支持、XML Schema 支持以及用于大文档或流化文档的基于事件的处理。
5、JDOM,DOM4J解析实例
5.1 JDOM
被解析的xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<database>
<url>jdbc:mysql://localhost:3306/studentinfo?characterEncoding=UTF-8</url>
<user>root</user>
<pwd>123123</pwd>
<driver>com.mysql.jdbc.Driver</driver>
</database>JDOM解析:
public class JDOM {
public static void main(String[] args) {
long lasting = System.currentTimeMillis();
try {
String path=DOM4Java.class.getClassLoader().getResource("")
.toString().substring(6);
SAXBuilder builder = new SAXBuilder();
Document doc = builder.build(new File(path+"database.xml")); //获得xml文件的位置
Element foo = doc.getRootElement();//得到根节点
List allChildren = foo.getChildren();
for(int i=0;i<allChildren.size();i++)
{
//遍历子节点
System.out.println(((Element)allChildren.get(i)).getText());
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("运行时间:" + (System.currentTimeMillis() - lasting) + "毫秒");
}
}
输出:

5.2 DOM4J
xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<Result>
<VALUE>
<NO DATE="2005">A1</NO>
<ADDR>GZ</ADDR>
</VALUE>
<VALUE>
<NO DATE="2004">A2</NO>
<ADDR>XG</ADDR>
</VALUE>
<note>
<NO DATE="2014">A4</NO>
<ADDR>XGgggg</ADDR>
</note>
</Result>DOM4J:
public class DOM4Java
{
public static void main(String[] args)
{
long lasting = System.currentTimeMillis();
try {
String path=DOM4Java.class.getClassLoader().getResource("")
.toString().substring(6);// 获得绝对路径
File f= new File(path+"demo.xml");
SAXReader reader = new SAXReader();
Document doc = reader.read(f);
Element root = doc.getRootElement(); //得到根节点
System.out.println(root.getName());
Iterator it = root.elementIterator("VALUE");//迭代器,获取root下所有value 子标签
while(it.hasNext())
{
Element foo = (Element) it.next(); //得到value
Element subfoo=foo.element("NO"); //获取value 下NO 子标签
System.out.print("车牌号码:" + foo.elementText("NO")+" 属性:"
+subfoo.attributeValue("DATE"));
System.out.println("车主地址:" + foo.elementText("ADDR"));
}
System.out.println("-----------------------------------");
Element e=root.element("note");
System.out.println(e.elementText("NO"));
System.out.println(e.elementText("ADDR"));
Element sube = e.element("NO");
System.out.println(sube.attributeValue("DATE"));
}catch (Exception e)
{
e.printStackTrace();
}
System.out.println("运行时间:" + (System.currentTimeMillis() - lasting) + "毫秒");
}
}
输出:




