1、Session
讲一讲session。
因为HTTP是无状态协议,当需要前面请求的信息时,必须重传。这时就引入了session。
session是服务端创建的一个容器。当请求过来时,如果请求没有sessionID,那么服务端就要创建一个新的session,并将sessionID返回给客户端。下一次请求就可以带上这个sessionID得到session里面的数据。
cookie和session的区别?
- 存储位置:cookie的数据存放在浏览器中,session的数据存放在服务器中。
- 安全性:cookie不安全,考虑到安全应该使用session
- 存储大小:单个cookie的存储大小不能超过4K,并且一个站点最多保存20个cookie,session则没限制
- 性能:当访问增多,session会占用服务器的性能。
2、JAVA内存划分
五大区:堆区,java栈区,本地方法栈区,方法区,程序寄存器区
堆区:都是new出来的对象,释放都由垃圾回收器回收。
java栈区:存放方法调用信息。
本地方法栈区:存放方法的局部变量。
方法区:存放静态变量和静态方法。
PC寄存器区:存储当前执行的指令。
Q/A:堆和栈有什么区别?
堆空间可以由程序员自己分配和释放,存放的都是new出来的对象。
栈空间是由编译器自动分配释放,存放的可以是方法信息和局部变量。
Q/A:类加载器是什么?
它可以把class文件加载到内存中,并生成相应的class对象。
分类:根类,扩展类,系统类,集成系统,自定义类加载器。
Q/A:什么是内存泄漏?怎么解决?
申请了内存空间而没有释放,比如一个不使用的对象一直占用着内存空间,但是这个对象存在着引用,所以垃圾回收器无法清理。
将不使用的对象置为null,当方法执行完毕后,垃圾回收器就会清理它们。但是只能解决一部分内存泄漏。有专业的工具,这些工具从JVM获取内存信息的方法有两种:JVM TI 和字节码技术。
3、垃圾回收器
3.1 要回收哪些区域?
堆区和方法区。
其他的区域它们的生命周期和线程是同步的,当线程销毁时,它们占用的内存也会自动销毁,所以不需要回收。
3.2 如何判断对象存活?
引用计数法
堆中的每一个对象都有一个引用计数。当该对象被引用一次,计数器+1,当计数器为0时,回收该对象。
优点:实现简单,效率高。
缺点:存在两个对象之间的相互引用。所以java语言没有用这个方法。
可达性分析算法
将所有的引用关系看作一张图,从一个节点GC ROOT开始向下寻找引用关系,当有对象不存在向下的引用关系是,判断为回收对象。
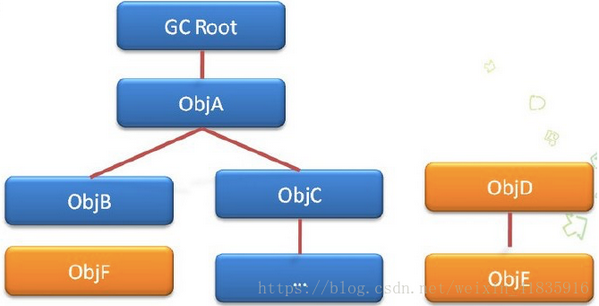
在Java语言中,可作为GC Roots的对象包括下面几种:
a) 虚拟机栈中引用的对象(栈帧中的本地变量表);
b) 方法区中类静态属性引用的对象;
c) 方法区中常量引用的对象;
d) 本地方法栈中JNI(Native方法)引用的对象。3.3 最常用的垃圾回收算法
分代收集算法:
分代收集算法是目前大部分JVM的垃圾收集器采用的算法。它的核心思想是根据对象存活的生命周期将内存划分为若干个不同的区域。一般情况下将堆区划分为老年代(Tenured Generation)和新生代(Young Generation),在堆区之外还有一个代就是永久代(Permanet Generation)。老年代的特点是每次垃圾收集时只有少量对象需要被回收,而新生代的特点是每次垃圾回收时都有大量的对象需要被回收,那么就可以根据不同代的特点采取最适合的收集算法。
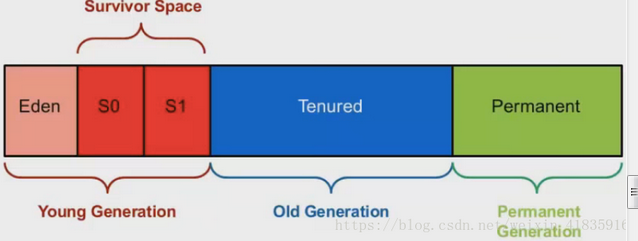
内存被分为下面三个区域:
① 新生代:Enden、form survicor space、to survivor space。
② 老年代 :
③ 永久代:方法区
新生代的回收算法:
包含有Enden、form survicor space、to survivor space三个区,绝大多数最新被创建的对象会被分配到这里,大部分对象在创建之后会变得很快不可达。
① 所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。
② 新生代内存按照8:1:1的比例分为一个eden区和两个survivor(survivor0,survivor1)区。一个Eden区,两个 Survivor区(一般而言)。大部分对象在Eden区中生成。回收时先将eden区存活对象复制到一个survivor0区,然后清空eden区,当这个survivor0区也存放满了时,则将eden区和survivor0区存活对象复制到另一个survivor1区,然后清空eden和这个survivor0区,此时survivor0区是空的,然后将survivor0区和survivor1区交换,即保持survivor1区为空, 如此往复。
③ 当survivor1区不足以存放 eden和survivor0的存活对象时,就将存活对象直接存放到老年代。若是老年代也满了就会触发一次Full GC,也就是新生代、老年代都进行回收。
④ 新生代发生的GC也叫做Minor GC,Minor GC发生频率比较高(不一定等Eden区满了才触发)。
老年代的回收算法:
① 在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
② 内存比新生代也大很多(大概比例是1:2),当老年代内存满时触发Major GC即Full GC,Full GC发生频率比较低,老年代对象存活时间比较长,存活率标记高。
永久代的回收算法:
用于存放静态文件,如Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate 等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代也称方法区。
3.4 常见的垃圾回收器
Serial收集器,Serial Old收集器,ParNew收集器,Parallel Scavenge收集器,Parallel Old收集器,CMS收集器
3.5 GC是什么时候触发的?
GC有两种类型,Minor GC和Full GC。
Minor GC:
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Minor GC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。这种方式的GC是对年轻代的Eden区进行,不会影响到年老代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden去能尽快空闲出来。
Full GC:
对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个堆进行回收,所以比Scavenge GC要慢,因此应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于Full GC的调节。有如下原因可能导致Full GC:
a) 年老代(Tenured)被写满;
b) 持久代(Perm)被写满;
c) System.gc()被显示调用;
d) 上一次GC之后Heap的各域分配策略动态变化;
Q/A:jvm查看gc命令:
jstat -gc 12538 5000
即会每5秒一次显示进程号为12538的java进成的GC情况,。
Q/A:如果老年代频繁回收怎么分析解决?
(个人理解)老年代是存放那些在程序中经历了好几次回收仍然还活着或者特别大的对象(这个大就要看你是否设置了-XX:PretenureSizeThreshold 参数了)。检查程序中是否有比较大的对象,或者这个参数设置是否合理。
3.6 参考资料
https://blog.csdn.net/weixin_41835916/article/details/81530733
4、JAVA为什么可以跨平台?
总的来说,java代码可以跨平台运行,主要是jvm是跨平台的。
因为java编译后是字节码。每个系统平台都有自己的jvm。java代码不是直接在电脑上运行的,而是在jvm虚拟机上运行的。
5、单例模式
5.1 什么是单例模式?
单例模式就是一个类只能有一个实例化对象,适用那些创建比较频繁和只需一个对象的类。
5.2 懒汉模式
懒汉模式,顾名思义,就是实例在被用到的时候才去创建。用的时候检查有没有实例,没有的话就创建一个返回。分线程安全和线程不安全两种写法,区别就是用synchronized关键字。
public class Lazy
{
private static Lazy lazy = null;
private Lazy() {
// TODO Auto-generated constructor stub
}
public Lazy getInstance()
{
if(lazy == null)
lazy = new Lazy();
return lazy;
}
}5.3 饿汉模式
饿汉模式就是“积极”。实例在初始化的时候就创建好了。优点是线程安全,缺点是浪费内存空间。
public class Hungry
{
private static Hungry hungry = new Hungry();
private Hungry() {
// TODO Auto-generated constructor stub
}
public Hungry getInstance()
{
return hungry;
}
}5.4 双检锁
双检锁,又叫双重校验锁,综合了懒汉式和饿汉式两者的优缺点整合而成。看上面代码实现中,特点是在synchronized关键字内外都加了一层 if 条件判断,这样既保证了线程安全,又比直接上锁提高了执行效率,还节省了内存空间。
public class DoubleCheck
{
private DoubleCheck instance = null;
private DoubleCheck() {
// TODO Auto-generated constructor stub
}
public DoubleCheck getInstance()
{
if (instance == null) {
synchronized (DoubleCheck.class) {
if (instance == null) {
instance = new DoubleCheck();
}
}
}
return instance;
}
}5.5 静态内部类
静态内部类的方式效果类似双检锁,但实现更简单。但这种方式只适用于静态域的情况,双检锁方式可在实例域需要延迟初始化时使用。
public class SingleTon
{
private static class SingleTonHolder
{
private static final SingleTon INSTANCE = new SingleTon();
}
private SingleTon(){
}
public static SingleTon getInstance()
{
return SingleTonHolder.INSTANCE;
}
}5.6 枚举
枚举的方式是比较少见的一种实现方式,但是看上面的代码实现,却更简洁清晰。并且她还自动支持序列化机制,绝对防止多次实例化。
public enum Single
{
Instance;
public void AnyMethod()
{
}
}5.7 小结
一般情况下,懒汉式(包含线程安全和线程不安全两种方式)都比较少用;饿汉式和双检锁都可以使用,可根据具体情况自主选择;在要明确实现 lazy loading 效果时,可以考虑静态内部类的实现方式;若涉及到反序列化创建对象时,大家也可以尝试使用枚举方式。
(数据库连接池)适合单例模式
6、SSM
SSM:Spring、SpringMVC、Mybatis
6.1 Spring
内核:
IoC/DI(控制反转/依赖注入)
AOP(面向切面编程)
6.1.1 讲一讲SpringIoC?
SpringIoc的意思就是控制反转,它还可以叫做DI(依赖注入)。
所谓IoC,就是用Spring容器去管理对象的生命周期和对象之间的关系。
当我们在日常的编码中,常常会使用new来创建一个对象。但是这种做法会使代码的耦合度提高,不便于日后的维护,升级。所以提出了IoC技术,当我们需要一个对象时,Spring容器会读取配置文件,自动装配,然后直接给我们返回一个对象。通过这种技术,可以使代码解耦,解决了硬编码的问题。
这种技术使用十分简单,但是我自己有写过一个Spring内核,模拟了这个过程。
首先,我用了两个HashMap,一个叫beanInfoMap,另一个叫activeBeanMap。
通过解析配置文件得到所有的bean对象,然后把对象的名字当作key,对象本身当作value存到beanInfoMap中。然后根据用户传入的name,去beanInfoMap中找到Bean对象,在通过这个Bean对象去activeBeanMap中找是否有创建好的Object对象。如果有的话就直接返回这个对象,没有的话则需要根据Bean对象里面的全限定名,得到字节码对象,实例化出一个空的Object对象,通过字节码对象,将类中的属性,参数类型,参数值装配到Object对象中。然后把name,Object对象放到activeBeanMap中,返回这个Object对象。
6.1.2 讲讲AOP技术?
AOP技术就是面向切面编程,是面向对象编程的补充和完善。
AOP技术就是给分散的对象引入公共行为。这种技术面向对象编程是做不到的,所以提出了AOP面向切面编程。通过AOP技术,减少了系统中的重复代码,降低了模块间的耦合度,有利于后期的维护和升级。
实现AOP的两种操作:
- JDK动态代理技术
- 字节码增强技术
JDK动态代理技术:
被代理类必须实现了接口。
生成一个Proxy的子类,让这个子类实现接口,重写接口的方法,每个方法动态调用中间代理类的invoke方法。
字节码增强技术:
被代理类可以不实现接口。
生成一个子类去继承被代理类,然后重写父类的方法,增加切片。
AOP技术我在自己的项目中也使用过,用AOP做了个分页功能。
首先,我用了两个HashMap。第一个叫queryMaps,把uuid当做key,查询出的所有数据当作value存进去。第二个叫queryMethodMaps,把方法原型和参数拼接后转为字符串当作key,uuid作为value。
我的整体思路就是当一次查询请求发到后端时,先看这个请求里面有没有uuid,如果有uuid,就直接根据uuid从queryMap取出数据就行了。如果没有uuid,那么再判断一下这个方法之前有没有被调用过,如果被调用过,就根据这个方法的全限定名,方法原型和参数的拼接去queryMethodMaps中取出uuid,然后再取出数据。
当上面都不满足时,说明这个数据从未被查询过,所以需要执行这个查询方法。使用AOP代理这个方法,查询出所有数据后,随机生成uuid,把他们放到queryMaps中,然后把这个方法的原型和参数拼接成一个字符串,和uuid一起存到queryMethodMaps中去,最后返回出uuid。
6.2 SpringMVC
SpringMVC是一种软件体系架构,是MVC的一个实现版本,它把软件体系分为三部分:Model模型、View视图、Controller控制器。
SpringMVC的优点:
- 分层设计,利于维护和升级,可重用。
- 天生与Spring框架集成。
- 让程序员可以更专注在业务层。
谈一谈SpringMVC?
流程:前端发出请求给Controller,Controller通过请求里的url到handlermapping中找handler,找到handler后发送给handleradpter执行,返回ModleAndView对象,然后交给视图解析器得到页面返回。但是现在我们都不走视图解析器这一套了,使用@Respnsebody注解,要求直接返回json或者基本数据类型。
当前端发送一个请求给控制器时,控制器会根据请求来的URL到HandleMapping中查找。HandleMapping中有两种映射方式。
第一种是BeanNameMapping,一个URL对应一个类的全限定名。如果URL在这里查到的话,就可以根据全限定名得到字节码,实例化一个对象,然后用接口回调技术去调用doGet或doPost方法。
第二种是annotationMethodMapping,一个URL对应一个类中的一个方法。URL在这里查到,首先得到字节码,实例化一个对象。然后根据方法名,参数类型,获取method对象。当方法无参,直接动态调用invoke函数。有参的情况下,就需要从请求里获取实参,装配给方法的参数。调用invoke函数。
之后则需要看如何处理数据,如果要求的是json则需要返回json,jsp同理。
6.3 Mybatis
Mybatis是一种持久层工具,它的底层是用反射机制实现的。
因为Mybatis的sql语句是写在xml配置文件中的,所以它比Hibernate更加灵活,但是它的可移植性不如Hibernate。
Q/A:#和$的区别?
#里传入的数据会被当成字符串,自动加上双引号。$里传入的数据是被直接拼接的。#可以防止注入攻击,$不能防止。
Q/A:常用的标签?
insert delete update select parameterType resultType include (foreach if where)动态sql 等
7、异常
异常是程序中发生的不可预料的错误,会影响程序的正常运行。
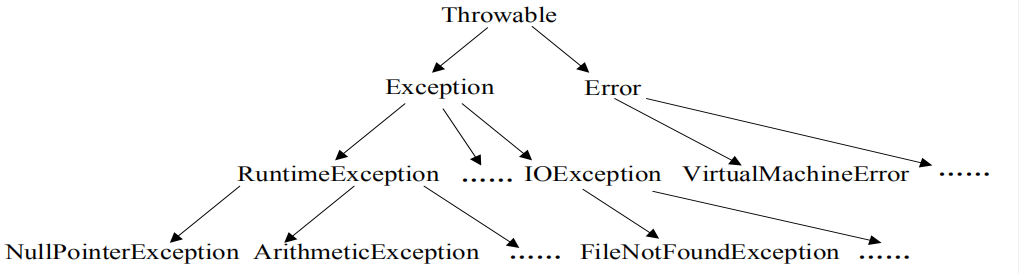
Throwable是所有异常的父类。它有两个子类,Exception和Error。Error类表示Java运行是产生系统内部错误,是程序无法解决的。Exception分为运行时异常和非运行时异常。
Error错误有:链接错误,系统内部错误等。
运行时异常有:空指针异常,数组越界异常等。
非运行时异常:找不到文件异常,IO中断异常等。
Java中可以使用Trows抛出异常,但这种是消极做法。常用的是try-catch捕获异常。把可能发生异常的代码放到try中,当发送异常时,用catch捕获异常并进行处理。最后的finnaly是一定会被执行到的,所以通常把文件的关闭,释放空间放在这里面。
(出现异常被catch捕获后就会进行捕获后的方法,try中不会执行下去)
我在自己的MVC中自己实现了自定义异常类,用来处理异常。
8、final,finally,finalize
final可以修饰属性,当修饰属性时这个属性就会变为常量,只可读,但不可修改。
可以修饰方法,表示该方法不可重写,但可以重载。
可以修饰类,表示这个类不可被继承。
finally:异常机制中使用finnaly修饰的代码块,finally代码块中的内容一定会被执行。
finalize:是方法名,它是由java提供的,在垃圾回收对象前执行的方法。它的作用是整理资源或执行其他清理操作。
9、自我介绍
你好,我叫孔令航,是南京邮电大学2021届毕业生,专业是软件工程,非常高兴可以参加贵公司的面试。我在大学学习期间一直以项目为驱动进行学习,保证自己能够掌握前沿的技术。所以在大二的时候,我就加入了老师的项目组,到目前为止一共参与过两个大型项目,分别是中小学学生管理系统,学校固定资产管理系统,除了这些大项目,我在学习过程中也做过很多小工具,例如ORMapping,聊天室等等。在学习之外,我也有一些自己喜欢做的事情,平时放松的时候喜欢听听歌,看动漫,打游戏,能够保证自己在学习和娱乐之间的平衡。
Hello, my name is Kong linghang. I’m a 2021 graduate of Nanjing University of Posts and telecommunications. I majored in software engineering. I’m very glad to have an interview with your company. During my university study, I have been project driven to ensure that I can master the cutting-edge technology. So when I was a sophomore, I joined the teacher’s project team. So far, I have participated in two large projects, namely, primary and secondary school student management system and school fixed assets management system. In addition to these large projects, I have also made many small tools in the learning process, such as ormapping, chat room, etc. In addition to learning, I also have some things I like to do. When I relax, I like listening to songs, watching cartoons and playing games, which can ensure the balance between learning and entertainment.
1.详细说说你的项目?
大二期间,我们开发了一个面向中小学的学生管理系统。我在里面的工作主要是学生注册模块,学生登录模块,学生选课模块。
学生注册模块我使用了一个帐号池来解决并发问题,重复刷号问题。学生登录模块做了一个帐号重复登录拦截的功能,还采用RSA加密算法保证帐号登录的安全性。学生选课模块我使用AOP技术做了个Application级别的分页,然后使用synchronized对选课操作加锁,解决并发问题。
大三期间又做了个固定资产管理的项目。我负责资产查询模块,资产调拨模块,用户登录模块。
在资产查询模块,因为数据库的数据量很大,读取速度很慢,所以为了提升速度,我让数据一部分一部分读,先读出一部分,当浏览到最后时,再继续读后面的数据。资产调拨模块就是员工申请一个资产的使用,这条记录就会被添加到调拨表里面,管理员那边可以看到调拨表里的请求,进行操作。用户登录模块跟之前那个项目差不多,都是做了个重复登录拦截的功能。
10、优缺点
优点:做事情认真,细心。比如我和朋友一起敲代码的时候,都是我帮他们改bug。做完一件事情也会反复检查有没有出错的地方。
缺点:性格有点腼腆,遇到不熟的人容易说不上话,但是混熟之后就好了。
11、与别人相比,你的优势
和本科生相比:我觉得我的优势在于技术更强,并且可以无缝进入企业中工作。
和研究生相比:我觉得我的技术也不输给它们,并且我还比他们更年轻。
12、高并发的问题
帐号池(开辟缓存区)线程回收学号,线程预防宕机。
13、数据库的锁机制
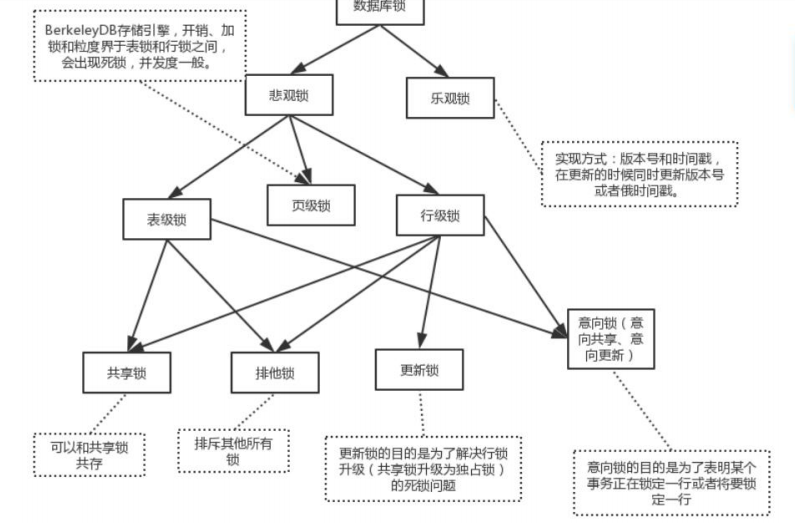
悲观锁适用增删改操作多的数据库,乐观锁适用查询操作多的数据库。
两种常用引擎:表级锁:MyISAM,行级锁:InnoDB
14、Redis有没有使用过,怎么使用?
当成缓存来用的。 自备份的两种方式RDB,AOF。
15、常用的Linux命令
cd:切换当前目录
pwd:显示当前目录
ls:查看当前目录下的文件
ping:测试网络是否连通
cat:查看文件内容
cp:复制文件
chmod:修改文件权限
rm -rf /…… 删除文件夹
rm -f/….. 删除文件
tail -n 100 Config.log 查看日志的后一百行
16、Spring常用注解
@Controller, @Service, @Repository,@Component,@Autowired,@Resource
@Autowired:Spring的注解,自动装配,默认按类型装配。
@Resoure:J2EE的注解,默认按name装配。
@Service(业务层),@Component,@Controller(表现层),@Responsitory(持久层):把对象作为bean注册进容器。
17、RPC
集群之间的服务通讯
18、谈谈未来技术的发展趋势
我目前了解到的知识
并不是所有项目适合前后端分离,web合适,别的不合适
19、死锁,活锁,饥饿
死锁是指两个或两个以上的线程,都持有自己的锁,并且都等对方释放锁资源,造成互相等待对方,如果没有外力推动,那么会一直等待下去。
活锁:两个线程都想获取一个锁资源,但是他俩都认为对方的优先级比他高,都在谦让对方,导致他俩都没办法进行下去。
饥饿:一个线程尽管能继续执行,但是被调度器一直忽视,导致一直无法运行。线程T1占用了资源R,T2请求封锁R,T3请求申请R,T1执行结束后调度器同意了T3的请求,T2一直被无视。
不公平锁可以提高吞吐量,但是会不可避免的造成某些线程的饥饿。
20、SpringMVC,Boot,Cloud
SpringBoot:微服务,大量简化MVC的配置,约定大于配置。简化SpringMVC开发的部署。
SpringCloud:管理微服务,提供注册机制,别人从这里拿。
21、Java基本数据类型和包装类
1字节:byte,boolean
2字节:short,char
4字节:int float
8字节:long,double
包装类就是基本数据类型首字母为大写的类,包装类的取值范围[-128,127]
//面试题:
Integer x1 = new Integer(10);
Integer x2 = new Integer(10);
System.out.println(x1==x2); //false ;双等号== 比较的是地址
System.out.println(x1.equals(x2));//true
Integer x3 = new Integer(128);
Integer x4 = new Integer(128);
System.out.println(x3==x4); //false
System.out.println(x3.equals(x4));//true
Integer x5 = 10;
Integer x6 = 10;
System.out.println(x5==x6); //true
System.out.println(x5.equals(x6));//true
Integer x7 = 128;
Integer x8 = 128;
System.out.println(x7==x8); //false ;Integer类中的享元模式,缓存里的最大值是127,所以超过最大值时就要创建对象了故比较返回false
System.out.println(x7.equals(x8));//true
Integer x9 = 127;
Integer x10 = 127;
System.out.println(x9==x10); //true
System.out.println(x9.equals(x10));//true22、重载和重写
重载就是在一个类中,几个方法,方法原型是一致的,但是参数的类型,或者参数的个数不一样,这就是重载,构造函数。
重写就是一个类继承或者实现一个接口,重写父类或者接口的方法。重写的方法必须与原方法完全一致,除了代码部分,重写的方法不能抛出比原方法更宽泛的异常,也不可以提升访问权限。
23、IP地址
IP地址就是网络号+主机号:
A类地址:1-126
B类地址:128-191
C类地址:192-223
D类是广播地址
E类留给将来使用
网络号全0就是本网络
主机号全0为主机地址,全1为网络地址
保留地址:
A类:10.0.0.0-10.255.255.255
B类:172.16.0.0-172.31.255.255
C类:192.168.0.0-192.168.255.255
24、JVM的参数
Xms 初始堆大小,一般是物理地址的1/64
Xmx 最大堆大小,一般是物理地址的1/4
Xmn 年轻堆大小
默认空余堆在40%时,就会把堆的大小推到Xmx,在70%时,就会推到Xms。
25、集合

ConcurrentHashMap:线程安全,比hashmap更高效。内部使用了分段锁,主干是个SegMent数组。一个segment数组就是一个子哈希表,对不同的segment数组操作不用考虑锁竞争。
26、线程
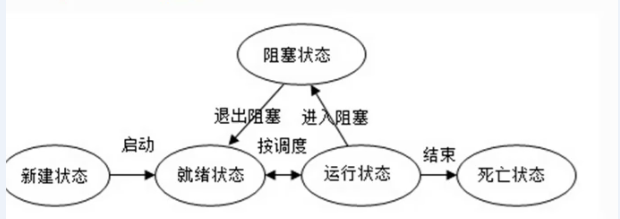
线程的生命周期:创建、就绪、运行、阻塞、死亡。
同步代码块和同步方法:
同步方法会给类的所有方法加同一把锁,方法不能同时进行。
同步代码块给特定的方法加特定的锁,别的方法可以同时进行。
死锁:
两个线程都有自己的锁,都在等待对方释放自己的锁。
volatile和syn:
volatile作用在变量上,不能保证原子性。
syn作用在变量,方法,类上,可以保证原子性。
volatile不会引起线程阻塞,syn会引起线程阻塞。
Lock和syn的区别:
Lock更精细一点,可以给不同的方法加不同的锁。
syn只能给所有的方法上同一把锁。
创建线程池的五个参数:
核心线程数,最大线程数,非核心线程的闲置时间,时间的单位,任务队列。
ThreadPoolExecutor.execute(Runnable) 提交任务
执行过程:
- 当核心线程数未满,就创建核心线程执行任务。
- 核心线程数满了,就把任务放到队列。
- 队列满了,就创建非核心线程执行任务。
- 队列满了,线程最大数也够了,就抛出异常。
常见的四种线程池:
可缓存线程池:没有核心线程,线程数量不限。在创建任务时,如果有空闲的线程就让它去做,没有就创建一个线程。当线程闲置60s就会被销毁。
定长线程池:线程数量就是核心线程的数量。如果当前线程数小于核心线程数,即使有闲置的线程,也会创建一个新的核心线程去执行任务。如果当前线程数大于核心线程数,就会用闲置的线程。
单线程池:就是一条线程,所有任务按照顺序执行。
延时线程池:不仅设置了核心线程数,总线程数也是这个。是唯一一种可以延时进行和周期执行任务的线程。
ThreadFactory就是一个线程接口,用来创建线程。
27、事务
事务就是一组要执行的操作,这组操作要么全部执行完,要么一个都不执行。
四个特性:ACID原子性,一致性,永久性,隔离性。
三种并发问题:脏读,不可重复读,幻读。
脏读:事务A修改了一个数据,事务B读了这个数据,但是事务A进行回滚操作,那么事务B读的这个数据就是脏读。
不可重复读:事务A一直读一条数据,事务B在A读数据的时候修改了这条数据,那么事务A两次读取的数据不一样,这就是不可重复。
幻读:事务A修改了表中的所有数据,但是B添加了一条数据,事务A发现所有数据中仍有一条未修改的数据,好像出现了幻觉。
四种隔离级别:读未提交,读已提交,可重复读(默认),串行化。
我还做过使用spring框架对事务的管理
编程式事务管理,声明式事务管理
编程式事务管理就是通过具体的代码实现,包括事务的开始,事务的完成,事务的回滚操作。
声明式事务管理就是通过AOP切片技术,把事务管理作为一个切面单独编写,移植到代码中,可以通过配置文件或者注解两种形式实现。
28、触发器和存储过程
触发器就是当用户对一张表做增删改的时候,可以同时对其他的表做操作。但是因为移植性太差,所以现在不使用。
存储过程就是数据库里的一段代码。需要调用才能使用。
29、数据库连接池
管理和释放数据库连接。它允许程序重复使用现有的数据库连接。常用的两个数据源:DB3P,C3P0
我也自己做过一个数据库连接池,用的单例模式。
30、union和union all的区别
都是合并两个查询结果。union会去掉重复记录,union all直接返回。
31、ajax技术
ajax是一种前端框架,可以在不重新加载整个页面的情况下,实现页面的局部更新,用来实现前后端分离。
使用到的技术:
- 使用xml和json进行数据交互。
- XMLHttpRequest进行异步数据接受。
- 使用JS将前面的技术绑定在一起。
请求参数:
- get,post,用来指定请求的类型。
- url
- 同步还是异步,true表示异步
使用步骤:
创建ajax对象(new XMLHttpRequst)
设置open
设置onReadyStateChange
设置send
32、request和session的区别
request用于提交表单数据,生命周期是http开始请求,服务端响应并返回数据的整个过程。
session用于存储数据,再整个会话期都有效,可以用来完成会话追踪。
request占用资源少,安全性高,但是缺乏持久性。session占用资源多,可以实现会话追踪。
33、redirect和forward
redirect是重定向,它会发送一个状态码给浏览器,让浏览器去请求新的url地址,会发送两次HTTP请求。
forward是请求转发,它会直接访问浏览器发过来的url,然后返回响应给浏览器,所以HTTP只用发送一次。
34、前后端通信的方式
根据HTTP协议通信,可以是浏览器发的请求,也可以使ajax发送的请求。
35、J2EE基本组件:Servlet,Filter,Listener
Servlet:是服务端的应用程序,可以动态生成web页面,在客户端请求和服务端响应的中间层。继承HttpServlet类,重写doGet,doPost方法。
Filter:过滤器,主要的作用是做一些编码转换,作用在请求到servlet之前,对所有的请求都会进行过滤操作,并且没有响应。
Listener:监听器。常用监听session的创建和销毁,可以用作统计网站在线人数。
执行顺序:Linstener>Filter>Servlet
36、Servlet的生命周期
加载并实例化,初始化,服务,销毁
当容器启动时,会加载servlet的class文件,实例化一个对象。
当第一个请求发给servlet时,调用init函数初始化。init函数在整个生命周期只能被调用一次。
然后调用service方法,用过这个方法调用doget和dopost方法。
如果长期不使用这个servlet,会自动销毁。
37、过滤器和拦截器
过滤器是J2EE组件,作用所有的请求,没有响应,依赖于servlet。编码转换
拦截器是SpringMVC的组件,只作用一部分请求,会有响应,不依赖servlet。权限管理。
38、NIO
39、微信公众号开发
40、 泛型擦除,上下限
泛型擦除:
当指定泛型类型时:ArrayQueueT<String> queue = new ArrayQueueT<String>();
编译器会报错queue.inQueue(99)
但是在字节码世界中,内部还是Object。
Class clz = queue.getClass();
try {
Method method = clz.getDeclaredMethod("inQueue", Object.class);
method.invoke(queue, 99);
Method method2 = clz.getDeclaredMethod("outQueue", null);
System.out.println(method2.invoke(queue, null));
} catch (Exception e) {
e.printStackTrace();
} 上下限:
普通的泛型:<T>
定义上限:<T extends Demo>,所有继承Demo的子类,包括Demo类,都可以作为T的参数。
定义下限:<T super SubDemo>,所有SubDemo的父类,包括SubDemo类,都可以作为T的参数。
41、栈溢出,堆溢出
堆溢出:OutOfMemoryError ,创建对象时没有足够的堆空间分配内存
ArrayList<Byte[]> list = new ArrayList<Byte[]>();
int i = 0 ;
while(true)
{
list.add(new Byte[5*1024*1024]);
i++;
System.out.println(i);
} 栈溢出:StackOverFlowError ,栈深度大于虚拟机提供的最大栈深度
public static void digui()
{
digui();
}
public static void main(String[] args)
{
digui();
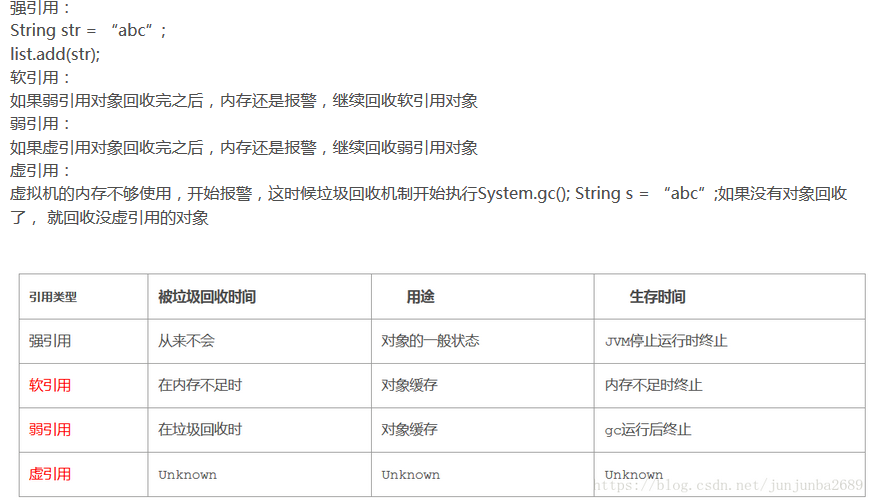
}42、强引用,软引用,弱引用,虚引用
String s = new String("qq"); //强引用
SoftReference<String> ss = new SoftReference<String>(s); //软引用
WeakReference<String> s3 = new WeakReference<String>(s); //弱引用
PhantomReference<String> s4 = new PhantomReference<String>(s, null); //虚引用Q/A:为什么提出这些引用?
Java是由Jvm负责分配和释放内存,这是它的优点。但是这种方式不够灵活,所有提出了这四种引用。有些一直需要的对象就用强引用,有些不关键的对象就用其他引用。
强引用:永远不会回收,Jvm宁愿抛出OutOfMemoryError异常,也不会回收这一类对象。
软引用:如果内存足够,就不会回收。当没位置了,就会回收它。软引用可以用来实现内存敏感的高速缓存。软引用可以用在浏览器的后退按钮。
弱引用:不管内存有没有空位,只要扫描到它,就会回收。
虚引用:就跟没有引用一样,在任何时候都会被回收。常用来跟踪对象被垃圾回收的活动。必须和引用队列联合使用。
43、switch–case
switch后的括号可以放哪些基本数据类型?
1字节:byte
2字节:short,char
4字节:int
8字节:
44、二叉搜索树
左子树小于根节点
右子树大于根节点
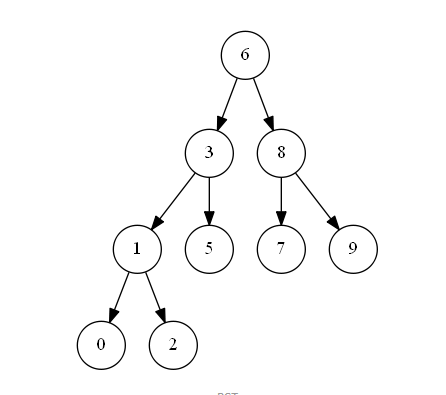
查询复杂度:深度越低,复杂度越低 O(logn—n)(二分查找)
Q/A:给定一颗二叉搜索树,给定树中的一个数,怎么查找它的上一个数?(非遍历)
45、进程和线程之间的通讯
进程通讯:消息队列、套接字、共享内存。
线程通讯:wait和notify,定义一个volatile修饰的全局变量控制。
46、两个项目的数据库设计
1. 中小学学生管理系统
* studentInfo
* professionInfo
* courseInfo
* scInfo- 固定资产管理
- userInfo
- assetsInfo
- user-assetsInfo
- applyInfo
47、Spring注解
@Controller(控制层) @Service(业务层) @Repositony(持久层) @Component(中立的类) 都是注解在类上面,当扫描器扫到这些类时会将它们创建为Bean对象保存在容器中。
@Autowired @Resource 注解在对象上面,自动为对象装配。
@Autowired 是Spring的注解,默认是按类型装配,想要使用名字装配可以配合@Qualifiter注解
@Resuorce 是J2EE的注解,默认按名字装配,其次是类型装配(推荐使用,解耦)
48、MVC的注解
@Controller注解表示扫描到这个类时,会自动把它加载到Spring的Bean工厂,并且对其实例化。
@RequestMapping就是一个映射路径,让我们访问到相应的方法。
@Response就是让返回的东西不走视图解析器,而是通过json或基本数据类型返回。

49、XML解析
四种解析方式:SAX,DOM,JDOM,DOM4J
流程:获取xml文件的位置,得到根节点,遍历子节点。
50、 双亲委托机制
核心思想:从底向上检查类是否被加载,从顶向下尝试加载类
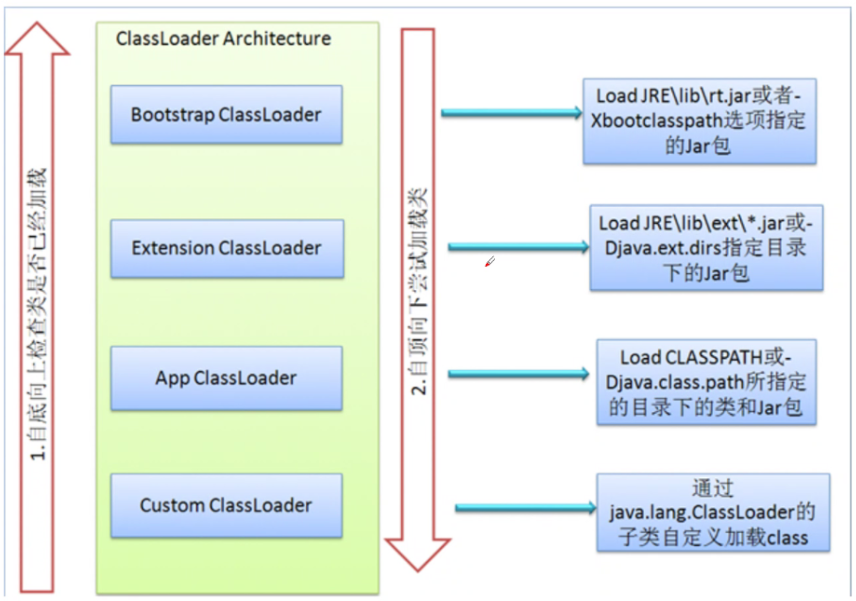
具体加载过程:
- 当APP ClassLoader加载一个class时,它首先不会自己去尝试加载这个类,而是把请求委派给父类加载器Extension去完成。
- Extension也不会尝试去加载,会委派给Bootstrap去完成。
- 如果Bootstrap加载失败,会让extension加载。
- extension加载失败,会给app加载。app加载也失败,会报出异常ClassNotFountException
51、集合的扩容
- ArrayList:默认容量为10,扩容1.5倍。 10 15 22 33 。。
- Vector:默认容量为10,扩容2倍。10 20 40 80。。
- Stack:继承于Vector,所以也是2倍速度扩容。
HashMap:默认容量16,加载因子0.75,扩容2倍,最大容量2的30次方
HashTable:默认容量11,加载因子0.75,扩容2倍加1
52、JDK1.8特性
接口中可以使用关键字defult,static定义方法并实现方法
lambda表达式。(使用lambda表达式必须有接口,并且接口只能有一个抽象方法。必须具有上下文推断)
函数式接口@FunctionalInterface。当接口的上面有这个时,这个接口只能定义一个抽象方法。
增加了日期类,线程安全LocalDateTime
Stream API 。流是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身不存储任何值。可以传入集合数组等,不改变原值,返回出持有结果的新流。
HashMap。 采用数据加链表加红黑树的数据结构。采用尾插法。
ConcurrentHashMap。采用CAS算法解决并发问题,而不是锁分段。数据结构也变为数组加链表加红黑树。
CAS算法就是compare and swap 比较交换算法。是乐观锁的实现,可以使用非阻塞方式来代替锁。在并发包下常被用到。会造成ABA问题。通过本地接口实现。
循环时间长,开销很大。
只能保证一个共享变量的原子操作。
ABA问题:线程A查询过一个数据为100,线程B在线程A下一次查询之前把数据-50又+50,线程A查询还是100.但期间这个数据被修改过。
通过加版本号的方式解决。
53、Get和Post的区别
他俩都是HTTP请求的方式。Http协议是基于TCP/IP协议的,所以这两种请求方式本质上是没有区别的。
网上的答案:
Get的请求数据是拼接在URL后面的,Post的请求数据是放在请求体中的。
Get效率比Post高。
Post安全性高。
Get请求数据有限制,因为URL的长度,Post无限制
Get的参数的数据类型必须数ASCII字符,Post无限制
但是,Get和Post都是基于TCP链接传输的,所以本质上是没有区别的。
这些只是HTTP提出的行为准则。Get请求也可以在请求体放数据,Post也可以在url后拼接数据。但是这么做有的服务器会全部读出,有的服务器则会忽略。大多数浏览器都会限制url的长度,所以会出现请求参数的限制。
Get和Post本质上都是TCP链接,并无差别。但是因为HTTP的规定和浏览器、服务器的限制,导致它们在实际过程中出现不同。
Get请求会产生一个TCP数据包,Post请求会产生两个TCP数据包。
Get会把header和data一起发送,返回数据浏览器会响应200.
Post会分两次发送,第一次header,响应100继续,第二次data,响应200
54、HTTP响应码
- 100:响应正常,可以继续发送请求
- 200:请求成功。
- 301:没有请求成功,必须采取进一步的动作。
- 404:请求资源不存在。
- 500:服务器内部错误,无法完成请求。
55、自定义注解
使用@interface声明一个注解。
public @interface Info {
String value() default "asd";
boolean isDelete();
}使用元注解规定范围。
@Documented //该注解标记的元素可以被文档化
@Retention(RetentionPolicy.RUNTIME) //注解的生命周期
@Target({ElementType.FIELD,ElementType.TYPE}) //可以应用的Java元素类型
@Inherited //该类的子类同样有注解
public @interface Info {
String value() default "asd";
boolean isDelete();
}写一个类,加注解
@Info(isDelete = true)
public class Person
{
private String name;
private int age;
private boolean isDelete;
}Main中通过反射测试注解
public static void main(String[] args) {
Person person = new Person();
Class clz = person.getClass();
if(clz.isAnnotationPresent(Info.class))
{
System.out.println("存在注解");
Info info = (Info)clz.getAnnotation(Info.class); //获取该对象上Info类型的注解
System.out.println(info.value()+" "+info.isDelete());
}
else {
System.out.println("不存在");
}
}56、RPC负载均衡
一个服务有多个请求地址的时候,会返回多个地址。RPC负载均衡就是我们要给哪台机器发出请求。
- 随机挑选
- 轮询
- LRU
- LFU
57、数据库和缓存数据不一致
并发量低的情况下:进行更新操作时,删缓存,再去改数据库,更新缓存,返回值。
并发量高的情况:
场景:有一个更新操作想要把商品数100改成99,先删除缓存,但是在没有更新好的情况下,另一个查询操作查数据,查缓存没有,再查数据库100,写入缓存,返回。但是更新好之后数据库是99,缓存是100.
解决方案:通过队列解决这个问题,创建任意个数的队列,如20个,然后将商品ID去hash值,向队列个数取模,将更新操作放入队列中,等更新操作完成后移除队列。此时来一个查询操作,可以先判断队列中有没有更新操作,如果有,就放到队列中,没有就直接查。
优化:如果有多个相同的查询操作,后面的操作就不用加到队列里,让他们循环读缓存,如果查询一段时间后缓存中还是没有,那就直接读数据库。



