Java程序是怎么运行的?
Q/A: JDK和Java的区别?
JDK是Java开发工具包,里面包括:JRE(Java运行环境),JVM(Java虚拟机)等。
Java是一种开发语言。
Q/A: Java程序是怎么运行的?
- 先把Java代码编译成字节码,也就是.java编译成.class。这个过程的大致流程是:Java源代码–>词法分析器–>语法分析器–>语义分析器–>字节码生成器–>字节码,其中任何一个节点执行失败就会造成编译失败。
- 把class文件放到Java虚拟机,这个虚拟机通常是Oracle自带的Hotspot JVM。
- JVM通过类加载器(Class Loader)装载class文件。
- 类加载完成后,会进行字节码校验,字节码校验之后JVM解释器会把字节码翻译成机器码交给操作系统执行。但不是所有的代码都是解释执行的,JVM提供了动态编译器(JIT),它能够在运行时将热点代码编译成机器码,这个时候字节码就变成了编译执行。
Q/A: Java虚拟机是如何判定热点代码的?
基于采样的热点判定
虚拟机会周期性检查各个线程的栈顶,若某些方法经常出现在栈顶,那这些方法就是“热点方法”。优点:简单。缺点:容易收到外界因素的影响。
基于计数器的热点判定
给每个方法、代码块建立一个计数器,统计它们的执行次数。当执行次数超过一定的阀值,就会判定它们是热点方法。
JVM使用的是基于计数器的热点判定方法。它使用了两种技术器:方法调用计数器和回边计数器,当到达一定的阀值就会触发JIT编译。
方法调用计数器:在client的阀值是1500,Server是10000次,可以通过虚拟机参数设置。但是JVM还存在热度衰减,时间段内方法的调用次数减少,计数器就减小。
回边计数器:统计方法中循环体的执行次数。
相关面试题:
Q/A: Java语言有哪些特点?
- 面向对象
- 跨平台
- 执行性能好,效率高
- 有大量API扩展
- 支持多线程
- 安全性高
Q/A: Java为什么可以跨平台?
Java执行流程:Java源文件编译成字节码,通过JVM运行Java程序。
JVM底层屏蔽了不同服务器类型之间的差异。所以每个平台只要运行JVM就可以运行Java程序了。
Q/A: JDK、JRE、JVM的区别?
JDK是Java开发工具包,提供了Java的开发环境和运行环境。
JRE是Java运行环境,为Java的运行提供所需环境。
JVM是Java虚拟机,所有的Java程序都是在JVM上运行的。
Q/A: 获取明天的当前时间?
使用LocalDataTime获取。
LocalDateTime time = LocalDateTime.now();
System.out.println(time);
time = time.plusDays(1);
System.out.println(time);
time = time.minusDays(-1);
System.out.println(time);Q/A: 跳出循环
可以在循环体前加一个唯一标识,然后break 唯一标识;
aaa:for(int i=0;i....)
for(int j=0....)
break aaa;Q/A: char可以存一个数字吗?
Java使用的是Unicode编码,无论是数字,符号,中文都占两个字节。一个char类型大小是两个字节,所以可以存储。
Q/A: 内存泄漏
一个不被使用的对象或变量,一直占据着内存就会造成内存泄漏。
ArrayList list = new ArrayList();
for(int i=0;i<100;i++)
{
Object o = new Object();
list.add(o);
o = null;
} 此时,虽然释放了对象,但是ArrayList仍然引用着这个对象,所以不能被回收。
list = null;即可解决。
基本数据类型和包装类
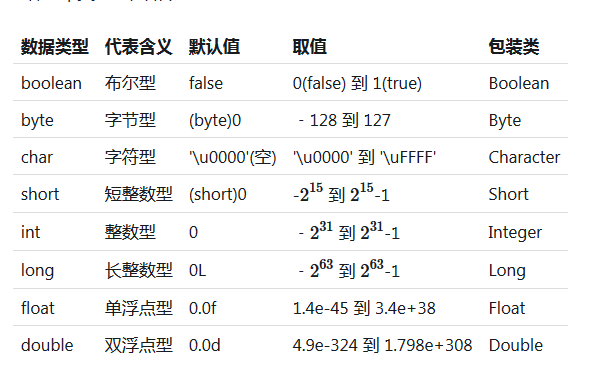
Q/A: 八种基本数据类型
1字节:boolean,byte
2字节:char,short
4字节:int,float
8字节:long,double
Q/A: 包装类的特性
功能丰富,有内置的方法。
可以用作泛型的参数。
序列化。
类型转换。Integer.parseInt();
高频区间的数据缓存。

Integer a = 127;
Integer b = 127; //a==b true
Integer a = 128;
Integer b = 128; //a==b false
int的默认值是0,Integer默认值是null;
Float和Double没有缓存。
Double a = 1.0;
Double b = 1.0;
System.out.println(a==b); //false
Float c = 1f;
Float d = 1f;
System.out.println(c==d); //false Integer是唯一可以修改缓存最大值的包装类。在VM OPTIONS 加入参数-XX:AutoBoxCacheMax=666 即修改缓存最大值为 666`
Q/A: 下面的程序输出什么?
final int iMax = Integer.MAX_VALUE;
System.out.println(iMax + 1);A:2147483648 B:-2147483648 C:程序报错 D:以上都不是
答案是B。整数在内存中是以补码的形式存在的,MAX_VALUE是2^31-1 = 2147483647
加1后最高位变成1,所以答案为-2^31。
Q/A: 如下图输出什么?

因为set里存储的是Short类型,(i-1)会将Short自动转换为Integer型。所以remove找不到Integer类型的数据,就一个也不删除。
自动转换,由下到上:byte–short–int—long—-float—double
强制转换,由上到下(必须手写,可能造成精度损失):double–float–long—int—short–byte
**Q/A: **
short s = 0;
s = s-1; //报错
s -= 1; //正常s = s-1 是先执行s-1,此时右边为int型,所以两边不匹配;
s -= 1 等效于 s = (short)s - 1;
Q/A: 为什么需要包装类?
- Java是面向对象的语言,万物皆对象。
- 包装类里有很多方法和属性。
Q/A: 泛型为什么不可以用基本数据类型?
例如List<Integer> list,在JVM编译时会变为List list,泛型擦除是为了兼容以前的代码。
泛型擦除后就变成了Object对象,Object对象不包括基本数据类型。
Q/A: 如何选择包装类和基本类?
正确的使用包装类可以提高效率。
所有PO类的对象都必须使用包装类。
- RPC技术的方法返回值和参数都必须使用包装类。
- 局部变量使用基本数据类型。
Q/A: 基本数据类型一定存储在栈中吗?
不一定。
局部变量存储在方法栈中。 全局变量存储在堆中。
字符串
Q/A: 字符串的特性
- String是标准的不可变类,对它的任何改动,其实就是创建一个新对象,然后引用指向该对象。
- String对象赋值后会自动在常量池中缓存,下一次创建会先判断常量池是否有缓存对象,如果有,直接返回该引用给创建者。
Q/A: 字符串截取
substring(int a,int b)
表示从a(包括a),到b(不包括b)的一段字符串
Q/A: 字符串格式化输出
String str = String.format("我是%s,今年%d岁", "ff",30);
System.out.println(str); Q/A: 字符串比较
String str = "hello,world";
String str1 = "HELLO,WORLD";
System.out.println(str==str1); //false
System.out.println(str.equals(str1)); //false
System.out.println(str.equalsIgnoreCase(str1)); //true,忽略大小写比较Q/A: String,StringBuffer,StringBuilder
String,StringBuilder线程不安全,Buffer和Builder都是可变的字符串,有append(),insert(),setCharAt()。
String字符串拼接本质上就是生成一个新对象,效率低。
StringBuffer通过Synchroized保证线程安全。多线程下用StringBuffer,单线程Builder效率高一点。
StringBuffer和StringBuilder都继承AbstractStringBuilder。
Q/A: ==和equals的区别?
== 当比较基本类型的时候,比较值,当比较引用类型的时候,比较地址。
equals默认是比较引用,但是很多类重写了这个方法,变成了比较值。
**Q/A: **
String s1 = "hi," + "lao" + "wang";
String s2 = "hi,";
s2 += "lao";
s2 += "wang";
String s3 = "hi,laowang";
System.out.println(s1 == s2); //false
System.out.println(s1 == s3); //true
System.out.println(s2 == s3); //false s2使用了+=,指向新的地址,地址不一样。
Q/A: String类中的intern()方法
String s1 = "123";
String s2 = s1.intern();
sysout(s1==s2); //true intern()就是判断字符串在常量池中是否有创建,如果不存在就先创建,存在就直接返回。
Q/A: String s = new String(“hello”);会创建几个对象?
一个或两个。如果hello在常量池中存在,那么就创建s去引用这个对象。如果不存在,就先在常量池创建一个,在创建s去引用。
Q/A: 什么是字符串常量池?
字符串常量池就是存储在堆空间的字符串池,为了防止每次创建字符串时间和空间过大。每当创建一个字符串时,JVM会先成字符串常量池找有没有该字符串,如果有,就将创建的字符串指向该地址,如果没有,就先创建一个字符串对象放到字符串常量池中,然后用新创建的对象指向该地址。
Q/A: 字符串不可变的好处?
- 当字符串不可变时,字符串常量池才可以存在。它节省了很大的堆空间。
- 避免安全漏洞。在Socket编程中,套接字是String,它的值是不可变的,当黑客侵入也改变不了。
- 多线程安全。
- 当作缓存的key,它在创建时哈希值就被计算出来存到缓存里去了,速度更快。
运算符和流程控制
Q/A: ++和–怎么做到线程安全?
- 使用synchroized同步代码块
- 自己声明锁
- 使用AtomicInteger 代替 int
Q/A: switch–case
可以用在switch中的有:
- byte,char,short,int
- enum(枚举)
- 字符串
异常处理
Q/A: 多catch块
JVM从上到下匹配异常类型,所以Exception类型不能放在最前面。
Q/A: 异常块对程序性能的影响
// 使用 com.alibaba.fastjson
JSONArray array = new JSONArray();
String jsonStr = "{'name':'laowang'}";
try {
array = JSONArray.parseArray(jsonStr);
} catch (Exception e) {
array.add(JSONObject.parse(jsonStr));
}
System.out.println(array.size());
如上述代码,利用异常处理完成业务功能。会产生额外的性能开销。
Q/A: 常见的运行时异常?
NullPointerException 空指针异常
非运行时异常:ClassNotFoundException 找不到文件异常
IndexOutOfBoundsException 数组越界异常
Q/A: Exception 和 Error
都是Throwable的子类。Error表示Java运行时程序内部出现错误,程序无法控制和解决。Exception分为运行时异常和非运行时异常,运行时异常编译可以通过,但是运行时出现这类未处理的异常,程序会中止运行。非运行时异常必须使用try–catch或者throws,否则编译不通过。
Q/A: throw和throws
throw作用在方法体里面,表示抛出异常由方法体内的语句处理,执行throw一定会抛出某种异常。
throws作用在方法声明后面,方法的调用者必须处理这种异常,throws代表可能会抛出异常,并不一定会发生这种异常。
**Q/A: **
Integer.parseInt(null);抛出NumberFormatException
Double.parseDouble(null);抛出NullPointerException
Q/A: 为什么try-catch耗费性能?
这个问题要从 JVM(Java 虚拟机)层面找答案了。首先 Java 虚拟机在构造异常实例的时候需要生成该异常的栈轨迹,这个操作会逐一访问当前线程的栈帧,并且记录下各种调试信息,包括栈帧所指向方法的名字,方法所在的类名、文件名,以及在代码中的第几行触发该异常等信息,这就是使用异常捕获耗时的主要原因了。
Q/A: 常见的OOM
- 数据库资源没有关闭
- 加载特别大的照片
- 递归次数过多,一直使用未释放的变量
Q/A: final,finally,finalize
final:修饰变量时,这个变量一定需要初始化,并且不可修改,只可读
修饰方法时,这个方法不能被重写。
修饰类时,这个类不能被继承。
finally:异常处理中的关键词,用finally修饰的代码块一定会被执行。
finalize:Object类中的方法,子类可以重写这个方法完成垃圾清理工作,垃圾回收之前会调用这个方法。
Q/A: 为什么finally代码块一定会被执行?
由于编译器在编译Java代码时,会复制finally的代码块的内容,并把内容放在try-catch所有正常执行路径及异常执行路径的出口,所以一定会被执行。
关于时间
JDK8之前都是使用Date,Clander类来操作时间,但是它们线程不安全,并且API调用麻烦。
JDK8之后新增了LocalDateTime,LocalDate,LocalTime等类,线程安全,操作方便。
数组和排序算法
使用for-each遍历数组
int[] a = {1,2,3,4,5};
for(int i:a)
sysout(i); 复制数组:Arrays.copyOf(a,a.length()),第二个参数可以超出原数组,超出的部分初始值为0;
数组转字符串:Arrays.toString(a) 输出为[1,2,3,4,5]
数组填充:Arrays.fill(a,6),将a数组值全部置为6
数组合并:a = ArrayUtils.addAll(a,b);
数组排序:Arrays.sort()
数组逆序:ArrayUtils.reverse(a)
数组查找:Arrays.binarySearch(a,3) 使用二分查找的数组必须排序,找不到返回-1
Q/A: 冒泡排序
public static void bubbleSort(int[] a)
{
for(int i=0;i<a.length;i++)
for(int j=1;j<a.length;j++)
if(a[j]<a[j-1])
{
int temp = a[j];
a[j] = a[j-1];
a[j-1] = temp;
}
}Q/A: 选择排序
public static void selectSort(int[] a)
{
for (int i = 0; i < a.length; i++) {
int minIndex = i; //每次选择排好的数组的后一个
for(int j= i+1;j<a.length;j++)
if(a[j]<=a[minIndex])
{
minIndex = j;
}
int temp = a[i];
a[i] = a[minIndex];
a[minIndex] = temp;
}
}
Q/A: 字符串转数组
String[] s = s1.split(String,Integer) 第一个参数是以什么分隔,第二个参数是分成几个数组。
Q/A: 数组转集合
List<String> list = Arrays.asList(res);
String[] aa = list.toArray(new String[list.size()]); System.out.println(Arrays.toString(aa));
Q/A: 集合和数组的区别?
- 集合可以存多种类型的数据,数组只能存单一类型。
- 集合长度会发生变化,数组长度固定
- 集合功能更多,数组效率高
Q/A: 数组的比较
String[] strArr = {"dog", "cat", "pig", "bird"};
String[] strArr2 = {"dog", "cat", "pig", "bird"};
System.out.println(Arrays.equals(strArr, strArr2)); //true
System.out.println(strArr.equals(strArr2)); //false
System.out.println(strArr == strArr2); //false Arrays中的equals被重写了,比较值。
数组没有重写,比较地址。
类与Object的应用
import可以导入静态方法和静态域
import static java.lang.System.*;
public class test1 {
public static void main(String[] args) {
out.print(11);
}
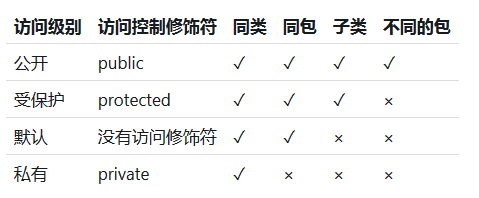
}四种修饰符:
public protected 默认 private
构造方法五大原则:
- 构造方法名一定要与类名相同
- 参数可以没有,可以有多个
- 构造方法可以有一个或多个
- 不能有返回值
- 伴随new出现
构造方法不能被继承,重写,直接调用,可以重载
Object类
它是所有类的父类。常用方法:
- equals():对比两个对象是否相同
- getClass():返回一个对象的运行时类
- hashCode():返回该对象的哈希码值
- toString():返回该对象的字符串描述
- wait():使当前的线程等待
- notify():唤醒在此对象监视器上等待的单个线程
- notifyAll():唤醒在此对象监视器上等待的所有线程
- clone():克隆一个新对象
类的组成部分
方法和变量
为什么不能多继承?
降低编程的复杂性。因为一个类同时继承类a,类b,但是类a和类b有相同的方法,子类重写时就会造成歧义。
重写和重载
重写:只能比父类抛出更少的异常,访问权限不能比父类方法低。
重载:一个类中有多个方法名相同的方法,但是参数不同。
调用顺序
class ExecTest {
public static void main(String[] args) {
Son son = new Son();
}
}
class Parent{
{
System.out.print("1");
}
static{
System.out.print("2");
}
public Parent(){
System.out.print("3");
}
}
class Son extends Parent{
{
System.out.print("4");
}
static{
System.out.print("5");
}
public Son(){
System.out.print("6");
}
}输出:251346
加载顺序:
- 执行父类的静态成员;
- 执行子类的静态成员;
- 父类的实例成员和实例初始化;
- 执行父类构造方法;
- 子类的实例成员和实例初始化;
- 子类构造方法。
重写:
class A {
public int x = 0;
public static int y = 0;
public void m() {
System.out.print("A");
}
}
class B extends A {
public int x = 1;
public static int y = 2;
public void m() {
System.out.print("B");
}
public static void main(String[] args) {
A myClass = new B();
System.out.print(myClass.x);
System.out.print(myClass.y);
myClass.m();
}
}输出:00B
在Java中,变量不能被重写。
重写
class A {
public void m(A a) {
System.out.println("AA");
}
public void m(D d) {
System.out.println("AD");
}
}
class B extends A {
@Override
public void m(A a) {
System.out.println("BA");
}
public void m(B b) {
System.out.println("BD");
}
public static void main(String[] args) {
A a = new B();
B b = new B();
C c = new C();
D d = new D();
a.m(a); //BA
a.m(b); //BA
a.m(c); //BA
a.m(d); //AD
}
}
class C extends B{}
class D extends B{}this,super
this和super都是关键字,起指代作用,在构造方法中必须出现在第一行。
- this是访问本类的属性和方法,super是访问父类的属性和方法
- this先查本类,没有的话再查父类,super直接查父类
- this单独使用时,表示当前对象,super在子类重写父类方法时,调用父类同名方法。
静态方法中为什么不可以使用this,super?
因为this,super指代的都是被创建出来的对象,而静态方法在类被加载的时候就已经创建了,所以静态方法中没办法使用this,super。
静态方法
静态方法中不能使用实例变量和实例方法。
静态方法中不能使用this,super。
重写equals()方法要遵循哪些规则?
自反性:对于任意非空的引用值 x,x.equals(x) 返回值为真。
对称性:对于任意非空的引用值 x 和 y,x.equals(y) 必须和 y.equals(x) 返回相同的结果。
传递性:对于任意的非空引用值 x、y 和 z,如果 x.equals(y) 返回值为真,y.equals(z) 返回值也为真,那么 x.equals(z) 也必须返回值为真。
一致性:对于任意非空的引用值 x 和 y,无论调用 x.equals(y) 多少次,都要返回相同的结果。在比较的过程中,对象中的数据不能被修改。
对于任意的非空引用值 x,x.equals(null) 必须返回假。
clone()方法
如果是同一个类使用,只需实现Cloneable接口,处理CloneNotSupportedException异常就可以了。
class CloneTest implements Cloneable {
int num;
public static void main(String[] args) throws CloneNotSupportedException {
CloneTest ct = new CloneTest();
ct.num = 666;
System.out.println(ct.num);
CloneTest ct2 = (CloneTest) ct.clone();
System.out.println(ct2.num);
}
} 如果不在同一个类,需要重写clone方法。
class CloneTest implements Cloneable {
int num;
public static void main(String[] args) throws CloneNotSupportedException {
CloneTest ct = new CloneTest();
ct.num = 666;
System.out.println(ct.num);
CloneTest ct2 = (CloneTest) ct.clone();
System.out.println(ct2.num);
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class CloneTest2 {
public static void main(String[] args) throws CloneNotSupportedException {
CloneTest ct = new CloneTest();
ct.num = 666;
System.out.println(ct.num);
CloneTest ct2 = (CloneTest) ct.clone();
System.out.println(ct2.num);
}
} 内部类和枚举类
Java内部类可以分为四种:
成员内部类,静态成员内部类,局部内部类,匿名内部类
内部类的优点:
- 内部类和外部类可以方便的访问彼此之间的私有域
- 内部类是另一种封装,对外部的其他类影藏。
- 解决单继承的局限。
1.成员内部类
class Outter11
{
public Outter11()
{
System.out.println(123);
}
class Inner
{
public void say()
{
System.out.println(1231234);
}
}
}成员内部类的创建:Inner inner = new Outter11().new Inner();
class Outer {
private String name = "OuterClass";
public void sayHi() {
System.out.println("Hi, Outer.");
}
class Inner {
public void sayHi() {
// 内部类访问外部类
Outer.this.sayHi();
System.out.println(Outer.this.name);
System.out.println("Hi, Inner.");
}
}
}
class InnerTest {
public static void main(String[] args) {
Outer.Inner inner = new Outer().new Inner();
inner.sayHi();
}
}内部类访问外部类:Outer.this.xxx;
外部类访问内部类:new Inner().xxx;
小结:
- 成员内部类可直接访问外部类(使用:外部类.this.xxx);
- 外部成员类要访问内部类,必须先建立成员内部类对象;
- 成员内部类可使用任意作用域修饰(public、protected、默认、private);
- 成员内部类可访问外部类任何作用域修饰的属性和方法;
- 外部类建立成员内部类对象之后,可以访问任何作用域修饰的内部类属性和方法。
- 成员内部类中不能有static修饰的变量或方法。
2.静态成员内部类
class OuterClass {
public OuterClass() {
System.out.println("OuterClass Init.");
}
protected static class InnerClass {
public void sayHi() {
System.out.println("Hi, InnerClass.");
}
}
}
class InnerClassTest {
public static void main(String[] args) {
OuterClass.InnerClass innerClass = new OuterClass.InnerClass();
innerClass.sayHi();
}
} 不能从静态内部类访问非静态外部类对象。
3.局部内部类
定义在一个类的局部(方法或者任何作用域)。
class OutClass {
public void sayHi() {
class InnerClass {
InnerClass(String name) {
System.out.println("InnerClass:" + name);
}
}
System.out.println(new InnerClass("Three"));
System.out.println("Hi, OutClass");
}
}局部内部类特点:
不能使用任何访问修饰符。
如果在方法中,可以直接使用方法中的变量,不需要Outclass.this.xxx调用
4.匿名内部类
interface AnonymityOuter {
void hi();
}
class AnonymityTest {
public static void main(String[] args) {
AnonymityOuter anonymityOuter = new AnonymityOuter() {
@Override
public void hi() {
System.out.println("Hi, AnonymityOuter.");
}
};
anonymityOuter.hi();
}
} 没有名字的内部类就是匿名内部类。
- 匿名内部类必须继承一个父类或者实现一个接口。
- 匿名内部类不能定义任何静态成员和方法。
- 匿名内部类的方法不能是抽象的。
枚举类:
enum ColorEnum
{
RED,BLANK,WHITE,YELLOW
}
public class enumTest {
public static void main(String[] args) {
ColorEnum colorEnum = ColorEnum.RED;
System.out.println(colorEnum);
}
} 枚举类其实就是特殊的常量类,它的构造方法默认为私有。
枚举类不能被继承,可以被序列化,线程安全。
扩展枚举类:
enum ColorsEnum {
RED("红色", 1),
BLUE("蓝色", 2),
YELLOW("黄色", 3),
GREEN("绿色", 4);
ColorsEnum(String name, int index) {
this.name = name;
this.index = index;
}
private String name;
private int index;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
}
class EnumTest {
public static void main(String[] args) {
System.out.println(ColorsEnum.RED.getName());
System.out.println(ColorsEnum.RED.getIndex());
}
}使用静态内部类的好处?
- 可以直接通过“外部类.内部类”的方式直接访问。
- 内部类可以访问外部类的静态方法和变量。
为什么使用内部类?
- 解决无法多继承的问题。
- 可以将一些逻辑相似的类放在一起,对外界影藏。
为什么使用枚举类?
- 作为高级的常量类
public enum Color {
RED("#FF0000", "255,0,0"),
GREEN("#00FFFF", "0,255,255"),
YELLOW("#FFFF00", "255,255,0");
String hex, rgb;
Color(String hex, String rgb) {
this.hex = hex;
this.rgb = rgb;
}
}- 方便switch的判断
switch(color)
{
case RED:
System.out.println("红灯停");
break;
case GREEN:
System.out.println("绿灯行");
break;
case YELLOW:
System.out.println("看情况");
break;
default:
System.out.println("灯坏了");
}枚举类在JVM中是如何实现的?
枚举类在编译后,它的属性会变成static final 修饰的常量。
抽象类和接口
抽象类:
一个类中没有足够的信息描绘一个具体的对象,这样的类就是抽象类。
- 抽象类不能被初始化
- 抽象类可以有构造方法
- 抽象类的子类如果为普通类,则必须重写抽象类中的所有抽象方法
- 抽象类中的方法可以是抽象方法或普通方法
- 一个类中如果包含了一个抽象方法,这个类必须是抽象类
- 子类中的抽象方法不能与父类中的抽象方法同名
- 抽象方法不能为 private、static、final 等关键字修饰
- 抽象类中可以包含普通成员变量,访问类型可以任意指定,也可以使用静态变量(static)
接口:
接口是抽象类的延伸,弥补了不能多继承的问题。
Java8接口的改动:
- 可以使用static,defult修饰方法,可以有方法体
interface School
{
static void say()
{
System.out.println("i am school");
}
default void eat()
{
System.out.println("i am eating");
}
}static可以直接调用School.say(),defult必须实例化才能调用。
- 接口中的静态变量会被继承,静态方法不会被继承
interface IAnimal {
static String animalName = "Animal Name";
static void printSex() {
System.out.println("Male Dog");
}
}
class AnimalImpl implements IAnimal {
public static void main(String[] args) {
System.out.println(animalName);
IAnimal.printSex();
}
}- 新增函数式接口
@FunctionalInterface
interface IAnimal {
static String animalName = "Animal Name";
static void printSex() {
System.out.println("Male Dog");
}
default void printAge() {
System.out.println("18");
}
void sayHi(String name);
}
class FunctionInterfaceTest {
public static void main(String[] args) {
IAnimal animal = name -> System.out.println(name);
animal.sayHi("WangWang");
}
} 使用 @FunctionInterface 声明的函数式接口,抽象方法必须有且仅有一个,但可以包含其他非抽象方法。
接口不是类,是对类的一组行为的描述。
抽象类和接口的区别:
- 默认方法
- 抽象类可以有默认方法的实现
- JDK 8 之前接口不能有默认方法的实现,JDK 8 之后接口可以有默认方法的实现
- 继承方式
- 子类使用 extends 关键字来继承抽象类
- 子类使用 implements 关键字类实现接口
- 构造器
- 抽象类可以有构造器
- 接口不能有构造器
- 方法访问修饰符
- 抽象方法可以用 public / protected / default 等修饰符
- 接口默认是 public 访问修饰符,并且不能使用其他修饰符
- 多继承
- 一个子类只能继承一个抽象类
- 一个子类可以实现多个接口
克隆和序列化
对象的克隆:
实现Cloneable接口
实现Cloneable接口,覆盖
public Object clone()方法。若类中还有其他类的引用,则其他类中也必须覆盖clone方法。public class Point implements Cloneable { int x; int y; public Point() { } public Point(int x,int y) { this.x=x; this.y=y; } public int getX() { return x; } public void setX(int x) { this.x = x; } public int getY() { return y; } public void setY(int y) { this.y = y; } @Override public String toString() { return "Point [x=" + x + ", y=" + y + "]"; } @Override public Object clone() { Point p = null; try{ p = (Point)super.clone(); }catch(CloneNotSupportedException e) { e.printStackTrace(); } return p; } }public class Address implements Cloneable { private String add; Point center; public Address() { this.add=null; this.center=null; } public Address(String ss,Point center) { this.add=ss; this.center=center; }
public String getAdd() {
return add;
}
public void setAdd(String add) {
this.add = add;
}
@Override
public Object clone() {
Address addr = null;
try{
addr = (Address)super.clone();
addr.center=(Point)this.center.clone();
}catch(CloneNotSupportedException e) {
e.printStackTrace();
}
return addr;
}
public boolean test(Address o)
{
return this.add==o.add;
}
public boolean testCenter(Address o)
{
return this.center==o.center;
}
@Override
public String toString() {
return "Address [add=" + add + "]";
} }
```java
public class AppAddress {
public static void main(String[] args) {
Address add=new Address("aaa",new Point(3,3));
Address add2=(Address)add.clone();
System.out.println(add.test(add2)); //true
add2.setAdd("bbb");
System.out.println(add.test(add2)); //false
System.out.println(add.getAdd()); //aaa
add2.center.x=9;
System.out.println(add.testCenter(add2)); //false
}
} 当add2=add.clone()后,add2引用add的地址。当add2改变自己的属性值时,将不再引用add的地址,而是重新指向一块地址,为深拷贝。
clone方式深拷贝小结:
1.如果有一个非原生成员,如自定义对象的成员,那么就需要:
该成员实现Cloneable接口并覆盖clone()方法,不要忘记提升为public可见。
同时,修改被复制类的clone()方法,增加成员的克隆逻辑。
2. 如果被复制对象不是直接继承Object,中间还有其它继承层次,每一层super类都需要实现Cloneable接口并覆盖clone()方法。
与对象成员不同,继承关系中的clone不需要被复制类的clone()做多余的工作。
一句话来说,如果实现完整的深拷贝,需要被复制对象的继承链、引用链上的每一个对象都实现克隆机制。
前面的实例还可以接受,如果有N个对象成员,有M层继承关系,就会很麻烦。
2. BeanUtils
BeanUtils是一个工具类,类中提供了cloneBean(Object object)方法。
自己实现BeanUtils(反射机制):
public class BeanUtils
{
public static Object copyObject(Object obj)
{
if(obj==null) return null;
Class clz=obj.getClass();
Object temp=null;
try{
temp=clz.newInstance();
Field[] fields=clz.getDeclaredFields();
for (Field field : fields)
{
field.setAccessible(true);
Object value=field.get(obj);
if(check(field.getType()))
{
field.set(temp, value);
}
else
{
Object t=copyObject(value);
field.set(temp, t);
}
}
}catch(Exception e)
{
e.printStackTrace();
}
return temp;
}
private static boolean check(Class clz)
{
if(clz==Integer.class||clz==Integer.TYPE) return true;
if(clz==Double.class||clz==Double.TYPE) return true;
if(clz==Float.class||clz==Float.TYPE) return true;
if(clz==Boolean.class||clz==Boolean.TYPE) return true;
if(clz==Long.class||clz==Long.TYPE) return true;
if(clz==String.class) return true;
return false;
}
}public static void main(String[] args) throws IllegalAccessException, InstantiationException, InvocationTargetException, NoSuchMethodException {
// TODO Auto-generated method stub
Address add=new Address("aaa",new Point(3,3));
Address add2=(Address)BeanUtils.copyObject(add);
System.out.println(add.testCenter(add2)); //false
Address add3 =(Address)org.apache.commons.beanutils.BeanUtils.cloneBean(add);
System.out.println(add.test(add3)); //false
System.out.println(add.testCenter(add3)); //false
}3. 序列化
public class Person implements Serializable {
private String name;
private Integer age;
private Address address;
public Person deepClone() {
Person p2=null;
Person p1=this;
PipedOutputStream out=new PipedOutputStream();
PipedInputStream in=new PipedInputStream();
try {
in.connect(out);
} catch (IOException e) {
e.printStackTrace();
}
try(ObjectOutputStream bo=new ObjectOutputStream(out);
ObjectInputStream bi=new ObjectInputStream(in);) {
bo.writeObject(p1);
p2=(Person) bi.readObject();
} catch (Exception e) {
e.printStackTrace();
}
return p2;
}
} clone机制不是强类型的限制,比如实现了Cloneable并没有强制继承链上的对象也实现;也没有强制要求覆盖clone()方法。因此编码过程中比较容易忽略其中一个环节,对于复杂的项目排查就是困难了。
要寻找可靠的,简单的方法,序列化就是一种途径。
- 被复制对象的继承链、引用链上的每一个对象都实现java.io.Serializable接口。这个比较简单,不需要实现任何方法,serialVersionID的要求不强制,对深拷贝来说没毛病。
- 实现自己的deepClone方法,将this写入流,再读出来。俗称:冷冻-解冻。
serialVersionUID的作用是什么?
显示定义serialVersionUID之后,如果serialVersionUID 的值相同,那么就可以修改对象的字段,程序不会报错,之后给没有的字段赋值为null;没有显式定义的话,就不可以修改,程序会报错。
可序列化接口Serializalbe的作用?
它构成了序列化的核心,它本身并没有任何方法,它的作用就是标记某对象为可序列化对象,指示编译器用java序列化机制序列化该对象。
序列化的三种方式?
- 原生序列化方式
// 序列化和反序列化
class SerializableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 对象赋值
User user = new User();
user.setName("老王");
user.setAge(30);
System.out.println(user);
// 创建输出流(序列化内容到磁盘)
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("test.out"));
// 序列化对象
oos.writeObject(user);
oos.flush();
oos.close();
// 创建输入流(从磁盘反序列化)
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("test.out"));
// 反序列化
User user2 = (User) ois.readObject();
ois.close();
System.out.println(user2);
}
}
class User implements Serializable {
private static final long serialVersionUID = 5132320539584511249L;
private String name;
private int age;
@Override
public String toString() {
return "{name:" + name + ",age:" + age + "}";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}JSON格式
Json序列化的优点就是可读性比较高,易于调试。
// 序列化和反序列化
class SerializableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 对象赋值
User user = new User();
user.setName("老王");
user.setAge(30);
System.out.println(user);
String jsonSerialize = JSON.toJSONString(user);
User user3 = (User) JSON.parseObject(jsonSerialize, User.class);
System.out.println(user3);
}
}
class User implements Serializable {
private static final long serialVersionUID = 5132320539584511249L;
private String name;
private int age;
@Override
public String toString() {
return "{name:" + name + ",age:" + age + "}";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}Hessian方式
Hessian方式效率比原生方式效率更高,可以跨语言编程
// 序列化和反序列化
class SerializableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 序列化
ByteArrayOutputStream bo = new ByteArrayOutputStream();
HessianOutput hessianOutput = new HessianOutput(bo);
hessianOutput.writeObject(user);
byte[] hessianBytes = bo.toByteArray();
// 反序列化
ByteArrayInputStream bi = new ByteArrayInputStream(hessianBytes);
HessianInput hessianInput = new HessianInput(bi);
User user4 = (User) hessianInput.readObject();
System.out.println(user4);
}
}
class User implements Serializable {
private static final long serialVersionUID = 5132320539584511249L;
private String name;
private int age;
@Override
public String toString() {
return "{name:" + name + ",age:" + age + "}";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}使用克隆的好处?
- 方便
- 性能高:因为clone()方法是native方法,native是原生函数,使用操作系统底层的语言实现的,所以效率更高。
- 隔离性
深克隆和浅克隆
- 浅克隆:只会复制对象的值类型,而不会复制对象的引用类型;
- 深克隆:复制整个对象,包含值类型和引用类型。
序列化时某些成员不需要序列化
使用transient或者static修饰成员
序列化和反序列化的过程?
在 Java 中序列化由 java.io.ObjectOutputStream 类完成,该类是一个筛选器流,它封装在较低级别的字节流中,以处理序列化机制。要通过序列化机制存储任何对象,我们需要调用 ObjectOutputStream.writeObject(savethisobject) 方法,如果要反序列化该对象,我们需要调用 ObjectInputStream.readObject() 方法,readObject() 方法会读取字节,并把这些字节转换为对象再返回。
Collection
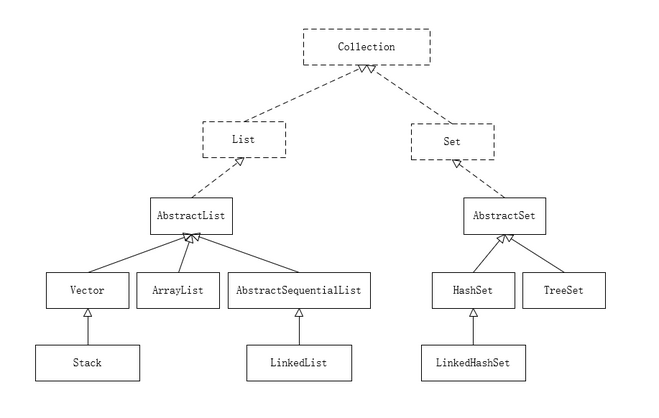
List:元素可重复,有序,适用于增删改
Set:元素不重复,无序,适用于元素唯一的场景
Vector
早期提供的线程安全的集合,但是效率很低。
ArrayList
最常见的线程不安全的集合,因为内部是数组存储的,所以随机访问效率很高,但是非尾部的插入和删除效率很低,会进行移位。
LinkedList
使用双向链表的集合,所以增加和删除效率高,但是随机访问不如ArrayList。提供了offer()和peek()
add和offer的区别:add用在list里,offer用在queue里。peek查看元素。
HashSet
没有重复元素的集合,它虽然是Set集合的子类,但是它内部是HashMap的实例。
public HashSet() {
map = new HashMap<>();
} HashSet默认容量是16,每次扩容1倍。
TreeSet
TreeSet实现了自动排序。
LinkedHashSet
按照元素的hascode值决定存放位置,但同时又使用链表维护元素的次序。
数组与集合的转换:Arrays.asList(),xxx.toArray();
l两种排序:
自然排序Comparable,定制排序Comparator
public static void main(String[] args) {
// TODO Auto-generated method stub
TreeSet set = new TreeSet(); //参数构造,默认采用自然排序
set.add(20); //整数默认的自然排序规则
set.add(30);
set.add(10);
set.add(12);
System.out.println(set);
TreeSet set1 = new TreeSet<>();
set1.add("hi"); //字符串默认的自然排序规则
set1.add("good");
set1.add("bj");
System.out.println(set1);
//存储自定义Student,采用自然排序规则,要让Student实现Comparable接口,制定排序规则
TreeSet set2 = new TreeSet();
Student s1 = new Student(10,"Tom");
Student s2 = new Student(1, "Jerry");
Student s3 = new Student(20,"Tim");
set2.add(s1);
set2.add(s2);
set2.add(s3);
System.out.println(set2);
//采用定制排序,在构造TreeSet对象时将排序器传入
TreeSet set3 = new TreeSet<>(new StudentComparator());
set3.add(s1);
set3.add(s2);
set3.add(s3);
System.out.println(set3);
}
}
class StudentComparator implements Comparator{
@Override
public int compare(Object o1, Object o2) {
// TODO Auto-generated method stub
Student s1 = (Student)o1;
Student s2 = (Student)o2;
return s1.getId() - s2.getId();
}
Student类重写Comparable接口:
@Override
public int compareTo(Object o) {
// TODO Auto-generated method stub
Student o1 = (Student)o;
return this.name.compareTo(o1.name);
}List和Set的区别?
- List可以有多个null值,Set只能有一个
- List可以有重复元素,Set不能有重复元素
- List有序,Set无序
Vector和ArrayList
初始容量都是10,Vector扩容1倍,ArrayList扩容0.5倍+1。HashSet初始容量16,加载因子为0.75,就是长度超过0.75时,进行扩容,扩容1倍。
Vector、ArrayList、LinkedList 有什么区别?
这三者都是 List 的子类,因此功能比较相似,比如增加和删除操作、查找元素等,但在性能、线程安全等方面表现却又不相同,差异如下:
- Vector 是 Java 早期提供的动态数组,它使用 synchronized 来保证线程安全,如果非线程安全需要不建议使用,毕竟线程同步是有性能开销的;
- ArrayList 是最常用的动态数组,本身并不是线程安全的,因此性能要好很多,与 Vector 类似,它也是动态调整容量的,只不过 Vector 扩容时会增加 1 倍,而 ArrayList 会增加 50%;
- LinkedList 是双向链表集合,因此它不需要像上面两种那样调整容量,它也是非线程安全的集合。
Vector、ArrayList、LinkedList 使用场景有什么区别?
Vector 和 ArrayList 的内部结构是以数组形式存储的,因此非常适合随机访问,但非尾部的删除或新增性能较差,比如我们在中间插入一个元素,就需要把后续的所有元素都进行移动。
LinkedList 插入和删除元素效率比较高,但随机访问性能会比以上两个动态数组慢。
HashSet如何做到元素不重复?
内部是HashMap,把要储存的数据当作key,value是一个相同的虚值PRESENT。用新的key覆盖旧的key,返回false。
Comparable 和 Comparator 有哪些区别?
Comparable 和 Comparator 的主要区别如下:
- Comparable 位于 java.lang 包下,而 Comparator 位于 java.util 包下;
- Comparable 在排序类的内部实现,而 Comparator 在排序类的外部实现;
- Comparable 需要重写 CompareTo() 方法,而 Comparator 需要重写 Compare() 方法;
- Comparator 在类的外部实现,更加灵活和方便。
Map
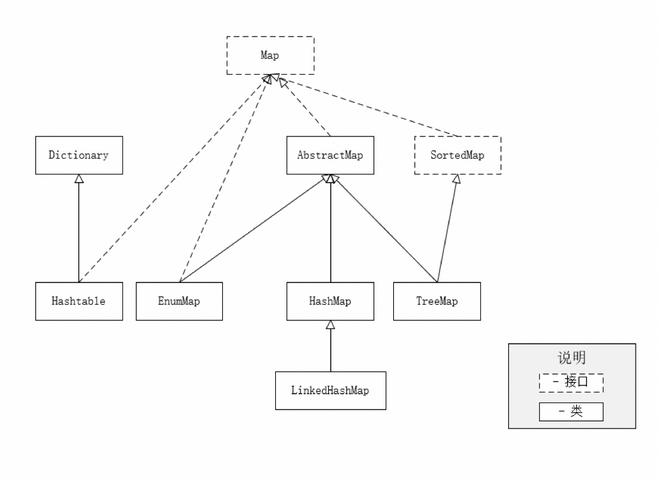
Map常用的类:
- HashTable:线程安全,不支持null键和值,性能不如ConcurrentHashMap,所以很少使用。
- HashMap:支持null键和值,单线程用HashMap,多线程用ConcurrentHashMap。
- TreeMap:基于红黑树,提供顺序访问的Map,自身实现了key的自然排序,也可以定制排序。
- LinkedHashMap:HashMap的子类,保存了记录的插入顺序,可以在遍历时保持与插入一样的顺序。
- ConcurrentHashMap:线程安全,不支持null作为键和值。
HashMap数据结构
数组加链表。在JDK8后,当链表长度大于等于8,数组长度大于64时,会转为红黑树存储。
使用HashMap可能会出现什么问题?如何避免?
HashMap 在并发场景中可能出现死循环的问题,这是因为 HashMap 在扩容的时候会对链表进行一次倒序处理,假设两个线程同时执行扩容操作,第一个线程正在执行 B→A 的时候,第二个线程又执行了 A→B ,这个时候就会出现 B→A→B 的问题,造成死循环。
解决的方法:升级 JDK 版本,在 JDK 8 之后扩容不会再进行倒序,因此死循环的问题得到了极大的改善,但这不是终极的方案,因为 HashMap 本来就不是用在多线程版本下的,如果是多线程可使用 ConcurrentHashMap 替代 HashMap。
TreeMap怎么实现value倒序?
使用 Collections.sort(list, new Comparator<Map.Entry<String, String>>() 自定义比较器实现,先把 TreeMap 转换为 ArrayList,在使用 Collections.sort() 根据 value 进行倒序,完整的实现代码如下。
TreeMap<String, String> treeMap = new TreeMap();
treeMap.put("dog", "dog");
treeMap.put("camel", "camel");
treeMap.put("cat", "cat");
treeMap.put("ant", "ant");
// map.entrySet() 转成 List
List<Map.Entry<String, String>> list = new ArrayList<>(treeMap.entrySet());
// 通过比较器实现比较排序
Collections.sort(list, new Comparator<Map.Entry<String, String>>() {
public int compare(Map.Entry<String, String> m1, Map.Entry<String, String> m2) {
return m2.getValue().compareTo(m1.getValue());
}
});
// 打印结果
for (Map.Entry<String, String> item : list) {
System.out.println(item.getKey() + ":" + item.getValue());
}HashMap 和 Hashtable 有什么区别?
HashMap 和 Hashtable 区别如下:
- Hashtable 使用了 synchronized 关键字来保障线程安全,而 HashMap 是非线程安全的;
- HashMap 允许 K/V 都为 null,而 Hashtable K/V 都不允许 null;
- HashMap 继承自 AbstractMap 类;而 Hashtable 继承自 Dictionary 类。
哈希冲突
两个不同的值,计算出的哈希值相同,这就叫做哈希冲突。
四种解决哈希冲突的方法
- 开放定址法:当关键字的哈希地址 p=H(key)出现冲突时,以 p 为基础,产生另一个哈希地址 p1,如果 p1 仍然冲突,再以 p 为基础,产生另一个哈希地址 p2,循环此过程直到找出一个不冲突的哈希地址,将相应元素存入其中。
- 再哈希法:这种方法是同时构造多个不同的哈希函数,当哈希地址 Hi=RH1(key)发生冲突时,再计算 Hi=RH2(key),循环此过程直到找到一个不冲突的哈希地址,这种方法唯一的缺点就是增加了计算时间。
- 链地址法:这种方法的基本思想是将所有哈希地址为 i 的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第 i 个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
- 建立公共溢出区:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
HashMap是用链表加红黑树解决哈希冲突的。
HashMap为什么扩容2^n?
让散列更加均匀,减少哈希碰撞,提高效率。
JDK7 JDK8 HashMap的区别?
- 存储结构:JDK 7 使用的是数组 + 链表;JDK 8 使用的是数组 + 链表 + 红黑树。
- 存放数据的规则:JDK 7 无冲突时,存放数组;冲突时,存放链表;JDK 8 在没有冲突的情况下直接存放数组,有冲突时,当链表长度小于 8 时,存放在单链表结构中,当链表长度大于 8 时,树化并存放至红黑树的数据结构中。
- 插入数据方式:JDK 7 使用的是头插法(先将原位置的数据移到后 1 位,再插入数据到该位置);JDK 8 使用的是尾插法(直接插入到链表尾部/红黑树)。
转红黑树的条件
数组长度到64,链表长度到8
泛型和迭代器
泛型的优点:
安全:不用担心程序运行过程中出现类型转换的错误。
避免了类型转换:如果是非泛型,获得的元素是Object类型的,需要强制类型转换。
可读性高:编码阶段就可以明确知道集合中元素的类型。
迭代器:
使用迭代器就可以不关注容器的内部细节,用同样的方法遍历不同的容器。
迭代器的next()方法返回的是Object,因为迭代器不关注内部细节。
HashMap的四种遍历方式:
- EntrySet方式
- 迭代器
- 遍历key和value
- 通过key遍历
以上方式的代码实现如下:
Map<String, String> hashMap = new HashMap();
hashMap.put("name", "老王");
hashMap.put("sex", "你猜");
// 方式一:entrySet 遍历
for (Map.Entry item : hashMap.entrySet()) {
System.out.println(item.getKey() + ":" + item.getValue());
}
// 方式二:iterator 遍历
Iterator<Map.Entry<String, String>> iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 方式三:遍历所有的 key 和 value
for (Object k : hashMap.keySet()) {
// 循环所有的 key
System.out.println(k);
}
for (Object v : hashMap.values()) {
// 循环所有的值
System.out.println(v);
}
// 方式四:通过 key 值遍历
for (Object k : hashMap.keySet()) {
System.out.println(k + ":" + hashMap.get(k));
}泛型可以修饰类,方法,接口,变量
List<Object>和List<?>的区别?
List<?>可以容纳任何类型,只不过被赋值后,不能添加和修改。
List<Object>也可以容纳所有类型,被赋值后,可以添加和修改。
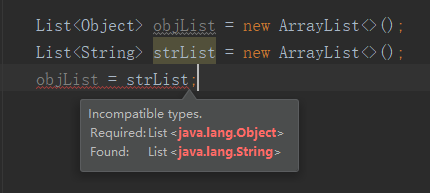
List 和 List<Object> 的区别是什么?
List 和 List<Object> 都能存储任意类型的数据,但 List 和 List<Object> 的唯一区别就是,List 不会触发编译器的类型安全检查,比如把 List<String> 赋值给 List 是没有任何问题的,但赋值给 List<Object> 就不行,如下图所示:

泛型的工作原理是什么?为什么要有类型擦除?
泛型是通过类型擦除来实现的,类型擦除指的是编译器在编译时,会擦除了所有类型相关的信息,比如 List<String> 在编译后就会变成 List 类型,这样做的目的就是确保能和 Java 5 之前的版本(二进制类库)进行兼容。
队列
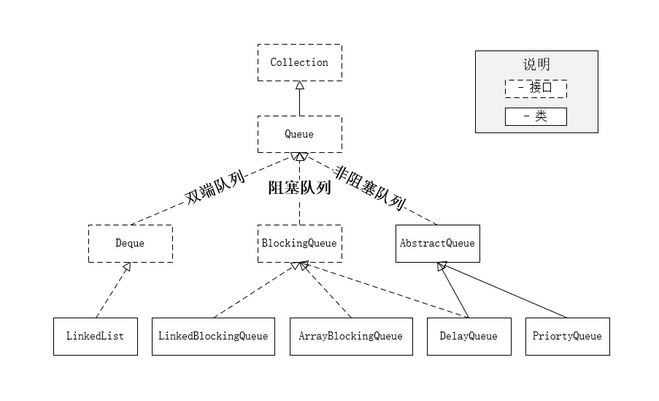
队列分类:
- 双端队列(Deque):头部和尾部都支持元素的插入和获取。
- 阻塞队列:阻塞队列是指在元素操作时(增加或删除),如果操作未成功,会阻塞等待执行。例如:当添加元素时,如果队列满了,队列会阻塞直到有新的空位生成插入。
- 非阻塞队列:非阻塞队列与阻塞队列相反,会直接返回操作的结果。双端队列也是非阻塞队列。
常见方法:
- add(E):添加元素到队列尾部,成功返回 true,队列超出时抛出异常;
- offer(E):添加元素到队列尾部,成功返回 true,队列超出时返回 false;
- remove(Object):删除元素,成功返回 true,失败返回 false;
- poll():获取并移除此队列的第一个元素,若队列为空,则返回 null;
- peek():获取但不移除此队列的第一个元素,若队列为空,则返回 null;
- element():获取但不移除此队列的第一个元素,若队列为空,则抛异常。
使用实例
Queue queue = new LinkedList();
queue.add("3");
queue.add("1");
queue.add("4");
queue.remove();
while(!queue.isEmpty())
{
System.out.println(queue.poll());
} 阻塞队列
BlockingQueue
BlockingQueue在java.util.concurrent包下,其他的阻塞队列都实现自BlockingQueue接口。BlockingQueue提供了线程安全的队列访问模式,当向队列中插入数据时,如果队列已满,线程会被阻塞,等待队列中元素被取出后在插入。当从队列中取出数据时,如果队列为空,线程会被阻塞,等待队列中有新元素倍插入后在获取。
新增的两个方法:
put():当队列没位置,添加元素时会一直阻塞下去。
take():获取并移除第一个元素,队列为空时会一直阻塞。
LinkedBolckingQueue
LinkedBolckingQueue是一个由链表实现的有界阻塞队列,默认容量是Integer.MAX_VALUE,也可以自定义容量。建议指定容量,因为默认大小时当添加速度大于删除速度时有内存溢出的风险。先进先出的方式。
ArrayBlockingQueue
ArrayBlockingQueue是一个由数组实现的有界阻塞队列,容量有限,初始化时必须指定容量大小,容量大小一旦被指定就不可改变。元素不允许为null。
ArrayBlockingQueue也是先进先出的方式,它的内部是由重入锁ReenterLock和Condition条件队列实现的。所以元素存在着公平访问和不公平访问的区别。对于公平的访问,会按照先阻塞的队列先访问的顺序。不公平访问就是所有阻塞的线程竞争,谁抢到就是谁的。
ArrayBlockingQueue<String> queue3 = new ArrayBlockingQueue<String>(5);//默认不公平访问 ArrayBlockingQueue<String> queue4 = new ArrayBlockingQueue<String>(5, true);//公平访问
DelayQueue
DelayQueue是一个支持延时获取元素的无界阻塞队列。队列中的元素必须实现Delayed接口,在创建元素时,指定延时的时间。只有经过延时时间后才能获取元素。
实现Delayed接口必须重写两个方法,getDelay(TimeUnit)和compareTo(Delay)。
class DelayElement implements Delayed { @Override // 获取剩余时间 public long getDelay(TimeUnit unit) { // do something } @Override // 队列里元素的排序依据 public int compareTo(Delayed o) { // do something } }完整例子:
public class DelayTest { public static void main(String[] args) throws InterruptedException { DelayQueue delayQueue = new DelayQueue(); delayQueue.put(new DelayElement(1000)); delayQueue.put(new DelayElement(3000)); delayQueue.put(new DelayElement(5000)); System.out.println("开始时间:" + DateFormat.getDateTimeInstance().format(new Date())); while (!delayQueue.isEmpty()){ System.out.println(delayQueue.take()); } System.out.println("结束时间:" + DateFormat.getDateTimeInstance().format(new Date())); } static class DelayElement implements Delayed { // 延迟截止时间(单面:毫秒) long delayTime = System.currentTimeMillis(); public DelayElement(long delayTime) { this.delayTime = (this.delayTime + delayTime); } @Override // 获取剩余时间 public long getDelay(TimeUnit unit) { return unit.convert(delayTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS); } @Override // 队列里元素的排序依据 public int compareTo(Delayed o) { if (this.getDelay(TimeUnit.MILLISECONDS) > o.getDelay(TimeUnit.MILLISECONDS)) { return 1; } else if (this.getDelay(TimeUnit.MILLISECONDS) < o.getDelay(TimeUnit.MILLISECONDS)) { return -1; } else { return 0; } } @Override public String toString() { return DateFormat.getDateTimeInstance().format(new Date(delayTime)); } } }结果:
开始时间:2019-6-13 20:40:38 2019-6-13 20:40:39 2019-6-13 20:40:41 2019-6-13 20:40:43 结束时间:2019-6-13 20:40:43
非阻塞队列
ConcurrentLinkedQueue
ConcurrentLinkedQueue是一个基于链表的无界线程安全队列。它采用先进先出的规则对节点进行排序。它的出队入队操作都使用CAS(Compare And Swap)更新,这样允许多个线程并发执行,并且不会因为加锁而阻塞线程,使得并发性能更好。
ConcurrentLinkedQueue concurrentLinkedQueue = new ConcurrentLinkedQueue(); concurrentLinkedQueue.add("Dog"); concurrentLinkedQueue.add("Cat"); while (!concurrentLinkedQueue.isEmpty()) { System.out.println(concurrentLinkedQueue.poll()); }
优先级队列
PriorityQueue
它是一个基于优先级堆的无界优先级队列。优先级队列可以根据自然排序或定制排序。优先级队列不允许使用null元素。
Queue<Integer> priorityQueue = new PriorityQueue(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
// 非自然排序,数字倒序
return o2 - o1;
}
});
priorityQueue.add(3);
priorityQueue.add(1);
priorityQueue.add(2);
while (!priorityQueue.isEmpty()) {
Integer i = priorityQueue.poll();
System.out.println(i);
}执行结果:3,2,1
PriorityQueue是线程不安全的,当多线程的情况下可以使用PriorityBlockingQueue替代。
PriorityQueue不允许插入null元素。
DelayQueue内部是基于PriorityQueue实现的。
ArrayBlockingQueue 和 LinkedBlockingQueue 的区别是什么?
ArrayBlockingQueue 和 LinkedBlockingQueue 都实现自阻塞队列 BlockingQueue,它们的区别主要体现在以下几个方面:
- ArrayBlockingQueue 使用时必须指定容量值,LinkedBlockingQueue 可以不用指定;
- ArrayBlockingQueue 的最大容量值是使用时指定的,并且指定之后就不允许修改;而 LinkedBlockingQueue 最大的容量为 Integer.MAX_VALUE;
- ArrayBlockingQueue 数据存储容器是采用数组存储的;而 LinkedBlockingQueue 采用的是 Node 节点存储的。
LinkedList 中 add() 和 offer() 有什么关系?
add()方法插入元素时,失败的话产生异常。
offer()方法插入元素时,失败的话返回false。
常见的阻塞队列
- ArrayBlockingQueue,由数组结构组成的有界阻塞队列;
- PriorityBlockingQueue,支持优先级排序的无界阻塞队列;
- SynchronousQueue,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素;
- LinkedBlockingQueue,由链表结构组成的阻塞队列;
- DelayQueue,支持延时获取元素的无界阻塞队列。
有界队列和无界队列的区别
有界队列和无界队列的区别如下。
- 有界队列:有固定大小的队列叫做有界队列,比如:new ArrayBlockingQueue(6),6 就是队列的大小。
- 无界队列:指的是没有设置固定大小的队列,这些队列的特点是可以直接入列,直到溢出。它们并不是真的无界,它们最大值通常为 Integer.MAX_VALUE,只是平常很少能用到这么大的容量(超过 Integer.MAX_VALUE),因此从使用者的体验上,就相当于 “无界”。



