Spring 核心功能
发展过程:
Spring1.x
此版本为了解决企业应用程序复杂性而创建的,当时J2EE应用的经典架构为分层架构:表现层,业务层,持久层。最流行的组合是SSH(Structs,Spring,Hibernate)。
Spring1.x仅支持基于XML的配置。
Spring2.x
变化不大,主要增加几个新的模块。
Spring3.x
Spring3.x开始不仅支持XML配置,还扩展了基于Java类的配置,还增加了Tomcat等组件,同时将原来的Web细分为Portlet和Servlet。
Spring4.x
提供RestFul风格,全面支持Java8。
Spring5.x
不断适配Java的新版本,同时重构优化自身核心框架代码,支持函数式、响应式编程模型等。
Spring核心
- 控制反转IoC
- 依赖注入DI
- 面向切面编程AOP
控制反转
顾名思义就是把创建对象的权利交给框架去控制,不需要人为的创建,这样实现了可插拔式的接口编程,有效地降低了代码耦合度,降低了扩展和维护的成本。
依赖注入
由容器动态的将某个依赖关系注入到组件中。依赖注入的目的并非为软件带来更多的功能,而是提升组件重用的频率,并为系统搭建一个灵活,可扩展的平台。只需通过简单的配置,就可以指定目标所用资源,完成自身业务逻辑。
IoC和DI的关系
IoC是Spring中的一个重要概念,DI则是实现IoC的方法和手段。依赖注入的常见方式:
- setter注入
- 构造方法注入
- 注解注入
Bean标签常用属性说明:
- id:为实例对象起名称,不能包含特殊符号
- name:功能跟id一样,但现在一般不用,可以包含特殊符号
- class:创建对象所在类的全限定名
- scope:一般最常用的有两个值,Singleton单例模式,整个应用程序只能创建一个Bean的实例;Prototype:原型模式,每次注入都创建一个新的实例。Spring默认创建的是单例模式。
AOP
优点
集中处理一类问题,方便维护
逻辑更加清晰
降低模块间的耦合度
AspectJ注解说明:
@Before 前置通知
@Around 环绕通知
@After 后置通知
@AfterReturning 返回通知
@AfterThrowing 异常通知
@Value注解的作用?
可以读取properties配置文件
@Value("#{configProperties['jdbc.username']}")
Spring 中 bean的作用域类型?
单例(Singleton):整个应用程序,只会创建一个Bean的实例
原型(Prototype):每次注入都会创建一个新的bean实例
会话(Session):每个会话创建一个bean实例,只在Web系统中有效。
请求(Request):每次请求创建一个bean实例,只在Web系统中有效。
Spring默认的是单例模式。
Spring中的JdbcTemplate对象
用来操作数据库。比JDBC提供更多的功能和有利的操作。
- JdbcTemplate是线程安全的。
- 实例化操作比较简单,仅需要传递DataSourse
- 自动完成资源的创建和释放工作
- 创建一次,到处可用,避免重复开发
Spring实现事务的两种方式
编程式事务
使用TransactionTemplate 或PlatformTransactionManager 实现。
声明式事务
底层是建立在AOP上的,在方法执行前后进行拦截,方法执行前创建新事物,执行后根据情况提交或回滚事务。
不需要编程,减少代码的耦合,在配置文件中配置,在目标方法上添加@Transactional注解来实现。
Spring声明式事务无效的可能原因?
- MySQL使用的是MyISAM引擎,MyISAM不支持事务
- @Transactional使用在非public方法上
- @Transactional 在同一个类中无事务方法 A() 内部调用有事务方法 B(),那么此时 B() 事物不会生效
Spring中的Bean是线程安全的吗?
Bean默认是单例模式,Spring没有对单例Bean进行多线程的封装处理,因此默认情况下是不安全的。可以将作用域设置为Prototype模式。
Spring优点
- 开源免费的热门框架,稳定性高、解决问题成本低;
- 方便集成各种优秀的框架;
- 降低了代码耦合性,通过 Spring 提供的 IoC 容器,我们可以将对象之间的依赖关系交由 Spring 进行控制,避免硬编码所造成的过度程序耦合;
- 方便程序测试,在 Spring 里,测试变得非常简单,例如:Spring 对 Junit 的支持,可以通过注解方便的测试 Spring 程序;
- 降低 Java EE API 的使用难度,Spring 对很多难用的 Java EE API(如 JDBC、JavaMail、远程调用等)提供了一层封装,通过 Spring 的简易封装,让这些 Java EE API 的使用难度大为降低。
Spring和Structs的区别
Spring 特性如下:
- 具备 IOC/DI、AOP 等通用能力,提高研发效率
- 除了支持 Web 层建设以外,还提供了 J2EE 整体服务
- 方便与其他不同技术结合使用,如 Hibernate、MyBatis 等
- Spring 拦截机制是方法级别
Struts 特性如下:
- 是一个基于 MVC 模式的一个 Web 层的处理
- Struts 拦截机制是类级别
Spring,Spring Boot,Spring Cloud
- Spring Framework 简称 Spring,是整个 Spring 生态的基础。
- Spring Boot 是一个快速开发框架,让开发者可以迅速搭建一套基于 Spring 的应用程序,并且将常用的 Spring 模块以及第三方模块,如 MyBatis、Hibernate 等都做了很好的集成,只需要简单的配置即可使用,不需要任何的 XML 配置文件,真正做到了开箱即用,同时默认支持 JSON 格式的数据,使用 Spring Boot 进行前后端分离开发也非常便捷。
- Spring Cloud 是一套整合了分布式应用常用模块的框架,使得开发者可以快速实现微服务应用。作为目前非常热门的技术,有关微服务的话题总是在各种场景下被大家讨论,企业的招聘信息中也越来越多地出现对于微服务架构能力的要求。
Spring中用到了哪些设计模式?
- 工厂模式:通过 BeanFactory、ApplicationContext 来创建 bean 都是属于工厂模式;
- 单例、原型模式:创建 bean 对象设置作用域时,就可以声明 Singleton(单例模式)、Prototype(原型模式);
- 观察者模式:Spring 可以定义一下监听,如 ApplicationListener 当某个动作触发时就会发出通知;
- 责任链模式:AOP 拦截器的执行;
- 策略模式:在创建代理类时,如果代理的是接口使用的是 JDK 自身的动态代理,如果不是接口使用的是 CGLIB 实现动态代理。
SpringMVC核心组件
SpringMVC是Spring框架提供的Web组件。
它的实现基于 MVC 的设计模式:Controller(控制层)、Model(模型层)、View(视图层),提供了前端路由映射、视图解析等功能,让 Java Web 开发变得更加简单,也属于 Java 开发中必须要掌握的热门框架。
运行流程:
- 客户端发送请求至前端控制器(DispatcherServerlt)
- 前端控制器根据请求路径,进入对应的处理器
- 处理器调用相应的业务方法
- 处理器获取到相应的业务数据
- 处理器把组装好的数据交还给前端控制器
- 前端控制器将获取的ModelAndView对象传给视图解析器
- 前端控制器获取到解析好的页面数据
- 返回给客户端
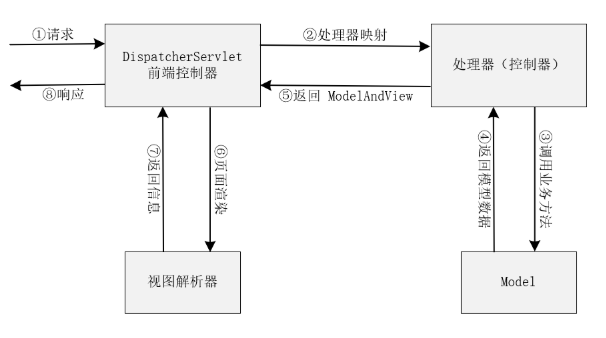
核心组件
DispacherServlet:核心处理器,负责调度其它组件的执行
Handler:处理器,完成具体的业务逻辑,相当于Servlet
HandlerMapping:DispacherServlet通过HandlerMapping将请求映射到不同的Handler
HandlerInterceptor:拦截器
HandlerExecutionChain:处理器执行链
HandlerAdapter:处理器适配器,Handler 执行业务方法之前,需要进行一系列的操作包括表单数据的验证、数据类型的转换、将表单数据封装到 POJO 等,这一系列的操作,都是由 HandlerAdapter 来完成,DispatcherServlet 通过 HandlerAdapter 执行不同的 Handler。
ModelAndView:返回结果
ViewResolver:视图解析器,DispacherServlet通过它将逻辑视图解析成物理视图,最终将渲染结果响应给客户端
自动类型转换
MVC可以将表单的内容,自动装配到实体类的对应属性上。
中文乱码处理
- 在web.xml中添加过滤器
- 设置RequestMapping的produces属性,指定返回类型和编码
POJO类和JavaBean
POJO类就是普通Java类,具有getter/setter方法。
当一个POJO类可序列化,有一个无参的构造方法,它就是一个JavaBean
如何实现跨域访问?
使用JSONP,或者在服务端设置运行跨域。
@RequestMapping注解常用属性
- value:指定 URL 请求的实际地址,用法:@RequestMapping(value=”/index”);
- method:指定请求的 method 类型,如 GET/POST/PUT/DELETE 等,用法:@RequestMapping(value=”/list”,method=RequestMethod.POST);
- params:指定请求参数中必须包含的参数名称,如果不存在该名称,则无法调用此方法,用法:@RequestMapping(value=”/list”,params={“name”,”age”})。
常见HTTP状态码
- 400:错误请求,服务器不理解请求的语法
- 401:未授权,请求要求身份验证
- 403:禁止访问,服务器拒绝请求
- 500:服务器内部错误
- 502:错误网关
- 504:网关超时
forward和redirect
- forward 表示请求转发,请求转发是服务器的行为;redirect 表示重定向,重定向是客户端行为;
- forward 是服务器请求资源,服务器直接访问把请求的资源转发给浏览器,浏览器根本不知道服务器的内容是从哪来的,因此它的地址栏还是原来的地址;redirect 是服务端发送一个状态码告诉浏览器重新请求新的地址,因此地址栏显示的是新的 URL;
- forward 转发页面和转发到的页面可以共享 request 里面的数据;redirect 不能共享数据;
- 从效率来说,forward 比 redirect 效率更高。
Spring MVC的常用注解:
- @Controller:用于标记某个类为控制器;
- @ResponseBody :标识返回的数据不是 html 标签的页面,而是某种格式的数据,如 JSON、XML 等;
- @RestController:相当于 @Controller 加 @ResponseBody 的组合效果;
- @Component:标识为 Spring 的组件;
- @Configuration:用于定义配置类;
- @RequestMapping:用于映射请求地址的注解;
- @Autowired:自动装配对象;
- @RequestHeader:可以把 Request 请求的 header 值绑定到方法的参数上。
拦截器的使用场景
- 日志记录
- 权限控制
- 统一安全处理
获取request的方式
- 从请求参数中获取
- 通过RequestContextHolder上下文获取request对象
- 通过自动注入的方式
SpringBoot
SpringBoot解决了Spring框架使用较为繁琐的问题。SpringBoot的核心思想是约定大于配置,让开发人员不需要任何XML文件,就可以像Maven整合Jar包一样,整合并使用所有框架。
特性
- 秒级构建一个项目
- 便捷的对外输出格式
- 简介的安全集成策略
- 内嵌容器运行
- 强大的开发包,支持热启动
- 自动管理依赖
- 自带应用监控
Spring、Spring Boot、Spring Cloud
它们都是Spring里的东西。Spring Boot是在Spring框架的基础上开发而来,可以更加方便的使用Spring;Spring Cloud是依赖于Spring Boot而构建的一套微服务治理框架。
Spring Boot的优势
- 开发变得简单,提供了丰富的解决方案,快速集成各种解决方案提升开发效率;
- 配置变得简单,提供了丰富的 Starters,集成主流开源产品往往只需要简单的配置即可;
- 部署变得简单,其本身内嵌启动容器,仅仅需要一个命令即可启动项目,结合 Jenkins、Docker 自动化运维非常容易实现;
- 监控变得简单,自带监控组件,使用 Actuator 轻松监控服务各项状态。
Ant、Maven、Gradle
都是Java领域中的三大构建工具。
Ant是最早的工具,但是它操作复杂被淘汰、
Maven目的是为了解决Ant的问题,它的好处在于可以将项目过程规范化、自动化、高效化、强大的可扩展性。
Gradle结合了前两者的优点,但是相比Maven来讲行业使用率偏低。SpringBoot默认使用Maven。
Spring Boot热部署的两种方式
Spring Loaded、Spring-boot-devtools
MyBatis
优点:
- 相比于 JDBC 需要编写的代码更少
- 使用灵活,支持动态 SQL
- 提供映射标签,支持对象与数据库的字段关系映射
缺点:
- SQL 语句依赖于数据库,数据库移植性差
- SQL 语句编写工作量大,尤其在表、字段比较多的情况下
执行流程:
- 首先加载 Mapper 配置的 SQL 映射文件,或者是注解的相关 SQL 内容。
- 创建会话工厂,MyBatis 通过读取配置文件的信息来构造出会话工厂(SqlSessionFactory)。
- 创建会话,根据会话工厂,MyBatis 就可以通过它来创建会话对象(SqlSession),会话对象是一个接口,该接口中包含了对数据库操作的增、删、改、查方法。
- 创建执行器,因为会话对象本身不能直接操作数据库,所以它使用了一个叫做数据库执行器(Executor)的接口来帮它执行操作。
- 封装 SQL 对象,在这一步,执行器将待处理的 SQL 信息封装到一个对象中(MappedStatement),该对象包括 SQL 语句、输入参数映射信息(Java 简单类型、HashMap 或 POJO)和输出结果映射信息(Java 简单类型、HashMap 或 POJO)。
- 操作数据库,拥有了执行器和 SQL 信息封装对象就使用它们访问数据库了,最后再返回操作结果,结束流程。
MyBatis和Hibernate区别?
它们都是ORM框架。
- 灵活性:MyBatis更加灵活,可以自己写语句。
- 可移植性:Mybatis因为有很多自己写的SQL语句,所以可移植性较差。
- 开发效率:Hibernate对SQL语句进行了封装,让开发者直接使用,所以开发效率更高。
- 学习和使用门槛:Mybatis入门比较简单,门槛也低。
为什么不建议在程序中滥用事务?
因为事务的滥用会影响数据的 QPS(每秒查询率),另外使用事务的地方还要考虑各方面回滚的方案,如缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
Mybatis的一级缓存和二级缓存
- 一级缓存是 SqlSession 级别的,是 MyBatis 自带的缓存功能,并且无法关闭,因此当有两个 SqlSession 访问相同的 SQL 时,一级缓存也不会生效,需要查询两次数据库;
- 二级缓存是 Mapper 级别的,只要是同一个 Mapper,无论使用多少个 SqlSession 来操作,数据都是共享的,多个不同的 SqlSession 可以共用二级缓存,MyBatis 二级缓存默认是关闭的,需要使用时可手动开启,二级缓存也可以使用第三方的缓存,比如,使用 Ehcache 作为二级缓存。
消息队列
应用场景?
- 应用解耦,比如,用户下单后,订单系统需要通知库存系统,假如库存系统无法访问,则订单减库存将失败,从而导致订单失败。订单系统与库存系统耦合,这个时候如果使用消息队列,可以返回给用户成功,先把消息持久化,等库存系统恢复后,就可以正常消费减去库存了。
- 削峰填谷,比如,秒杀活动,一般会因为流量过大,从而导致流量暴增,应用挂掉,这个时候加上消息队列,服务器接收到用户的请求后,首先写入消息队列,假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
- 日志系统,比如,客户端负责将日志采集,然后定时写入消息队列,消息队列再统一将日志数据存储和转发。
RabbitMQ是什么?
高级消息队列协议,用于在分布式系统中存储转发消息。
RabbitMQ的优点?
- 可靠性,RabbitMQ 的持久化支持,保证了消息的稳定性;
- 高并发,RabbitMQ 使用了 Erlang 开发语言,Erlang 是为电话交换机开发的语言,天生自带高并发光环和高可用特性;
- 集群部署简单,正是因为 Erlang 使得 RabbitMQ 集群部署变的非常简单;
- 社区活跃度高,因为 RabbitMQ 应用比较广泛,所以社区的活跃度也很高;
- 解决问题成本低,因为资料比较多,所以解决问题的成本也很低;
- 支持多种语言,主流的编程语言都支持,如 Java、.NET、PHP、Python、JavaScript、Ruby、Go 等;
- 插件多方便使用,如网页控制台消息管理插件、消息延迟插件等。
消息持久化:把消息保存到物理介质上,以防止消息的丢失。
MySQL
MySQL执行流程
- 客户端通过连接器与MySQL服务器连接
- 连接成功后,先查有没有缓存,有的话直接返回缓存数据,没有的话进入分析器。
- 分析器对SQL语句进行分析,看SQL语句是否正确,如果错误就返回错误信息,如果正确就进入优化器。
- 优化器对查询语句进行优化处理,优化完成后进入执行器
- 执行器通过SQL语句查找数据,返回
查询缓存的优缺点
优点:效率高
缺点:任何更新表的操作都会清空缓存,因此导致查询缓存非常容易失效
InnoDB和MyISAM
InnoDB是MySQL的默认存储引擎。
- InnoDB支持事务,MyISAM不支持事务
- InnoDB 支持崩溃后安全恢复,MyISAM 不支持崩溃后安全恢复;
- InnoDB 支持行级锁,MyISAM 不支持行级锁,只支持到表锁;
- InnoDB 支持外键,MyISAM 不支持外键;
- MyISAM 性能比 InnoDB 高;
- MyISAM 支持 FULLTEXT 类型的全文索引,InnoDB 不支持 FULLTEXT 类型的全文索引,但是 InnoDB 可以使用 sphinx 插件支持全文索引,并且效果更好;
- InnoDB 主键查询性能高于 MyISAM。
回表查询
普通索引查询到主键索引后,回到主键索引树搜索的过程,称之为回表查询。
InnoDB为什么使用B+树,而不使用B树、Hash、红黑树或二叉树?
- B 树:不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致 IO 操作变多,查询性能变低。
- Hash:虽然可以快速定位,但是没有顺序,IO 复杂度高。
- 二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且 IO 代价高。
- 红黑树:树的高度随着数据量增加而增加,IO 代价高。
MySQL如何处理死锁?
- 通过innodb lock wait timeout 来设置超时时间
- 发起死锁检测,发现死锁之后,主动回滚死锁中的某一个事务,让其他事务继续执行
全局锁
全局锁就是对整个数据库实例加锁,它的典型使用场景就是做全量逻辑备份,这个时候整个库会处于完全的只读状态。
全局锁的问题
使用全局锁会使整个系统不能执行更新操作,所有的更新业务会出于等待状态;如果你是在从库进行备份,则会导致主从同步严重延迟。
MySQL的性能指标
每秒查询数,每秒处理事务数。 可以通过show status查询。
表的优化策略
- 读写分离,主库负责写,从库负责读。
- 垂直分区,根据数据属性单独拆表甚至单独拆库。
- 水平分区,保持表结构不变,根据策略存储数据分片,这样每一片数据被分散到不同的表或者库中。水平拆分只是解决了单一表数据过大的问题,表数据还在同一台机器上,对于并发能力没有什么意义,因此水平拆分最好分库。另外分片事务难以解决,跨节点 join 性能较差
查询语句的优化
- 不做列运算,把计算都放入各个业务系统实现;
- 查询语句尽可能简单,大语句拆小语句,减少锁时间;
- 不使用 select * 查询;
- or 查询改写成 in 查询;
- 不用函数和触发器;
- 避免 %xx 查询;
- 少用 join 查询;
- 使用同类型比较,比如 ‘123’ 和 ‘123’、123 和 123;
- 尽量避免在 where 子句中使用 != 或者 <> 操作符,查询引用会放弃索引而进行全表扫描;
- 列表数据使用分页查询,每页数据量不要太大。
Redis
Redis就是内存型数据库,基于c语言。通过kv存储数据到内存中,读取速度很快。
应用场景
- 记录帖子点赞数、点击数、评论数
- 缓存近期热帖
- 缓存文章详情信息
- 记录用户会话信息
支持的数据类型
String字符串,List列表,Set无序集合,ZSet有序集合,Hash哈希
Redis中的key最大容量是512MB
Redis的数据结构
Redis的数据结构是跳跃表,跳跃表是基于链表的扩展,在普通链表的基础上增加了层的概念,层级越高元素越少,每次先从高层查找。
缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存中没有,因而每次需要从数据库中查询,但数据库也没有相应的数据,所以不会写入缓存,这就将导致每次请求都会去数据库查询,这种行为就叫缓存穿透。
解决方案:无论数据库是否能查到数据,都缓存起来。把没有数据的缓存结果的过期时间设置比较短的一个值。
缓存雪崩
指缓存由于某些原因,比如,宕机或者缓存大量过期等,从而导致大量请求到达后端数据库,进而导致数据库崩溃的情况。
解决方案:分析业务功能,把缓存的失效时间均匀分布。
Redis切换数据库
默认情况下客户端连接到数据库0,总共有16个,通过select 语句切换
Redis的集群策略?
增加 1 台机器作为哨兵,监控 3 台主从机器,当主节点挂机的时候,机器内部进行选举,从集群中从节点里指定一台机器升级为主节点,从而实现高可用。当主节点恢复的时候,加入到从节点中继续提供服务;
Redis持久化的两种方式
RDB,AOF
RDB:在指定时间间隔内,将内存中的数据集快照写入磁盘。它恢复是直接将快照读入内存。Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写进一个临时文件中,等到持久化过程结束了,再用这个临时文件替换上次持久化好的文件。
优点:
(1)如果要进行大规模数据的恢复,RDB方式要比AOF方式恢复速度要快。
(2)RDB可以最大化Redis性能,父进程做的就是fork子进程,然后继续接受客户端请求,让子进程负责持久化操作,父进程无需进行IO操作。
RDB是一个非常紧凑(compact)的文件,它保存了某个时间点的数据集,非常适合用作备份,同时也非常适合用作灾难性恢复,它只有一个文件,内容紧凑,通过备份原文件到本机外的其他主机上,一旦本机发生宕机,就能将备份文件复制到redis安装目录下,通过启用服务就能完成数据的恢复。
缺点:
(1) RDB这种持久化方式不太适应对数据完整性要求严格的情况,因为,尽管我们可以用过修改快照实现持久化的频率,但是要持久化的数据是一段时间内的整个数据集的状态,如果在还没有触发快照时,本机就宕机了,那么对数据库所做的写操作就随之而消失了并没有持久化本地dump.rdb文件中。
(2)每次进行RDB时,父进程都会fork一个子进程,由子进程来进行实际的持久化操作,如果数据集庞大,那么fork出子进程的这个过程将是非常耗时的,就会出现服务器暂停客户端请求,将内存中的数据复制一份给子进程,让子进程进行持久化操作。
AOF:以日志的形式记录Redis每一个写操作,将Redis执行过的所有写操作记录下来,只许追加不可以改写。
Redis的AOF是如何做到持久化的呢?
从配置文件中,我们可以发现
appendfsync always:每修改同步,每一次发生数据变更都会持久化到磁盘上,性能较差,但数据完整性较好。
appendfsync everysec: 每秒同步,每秒内记录操作,异步操作,如果一秒内宕机,有数据丢失。
appendfsync no:不同步。
数据恢复
重启Redis时,如果dump.rdb与appendfsync.aof同时都存在时,Redis会自动读取appendfsync.aof文件,通过该文件中对数据库的日志操作,来实现数据的恢复。当然如果该文件被破坏,我们可以通过redis-check-aof工具来修复,如redis-check-aof –fix能修复破损的appendfsync.aof文件,当然如果dump.rdb文件有破损,我们也可以用redis-check-rdb工具来修复,如果appendfsync.aof文件破损了,是启动不客户端的,也就是无法完成数据的恢复。
重写
当然如果AOF 文件一直被追加,这就可能导致AOF文件过于庞大。因此,为了避免这种状况,Redis新增了重写机制,当AOF文件的大小超过所指定的阈值时,Redis会自动启用AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用命令bgrewiteaof。
重写原理:AOF文件持续增长过大时,会fork出一条新进程来将文件重写(也是临时文件最后再rename),遍历新进程的内存中的数据,每条记录都会有一条set语句,重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新aof文件,有点类似于快照。
触发机制:Redis会记录上一次重写时的AOF大小,默认配置是当AOF文件大小是上一次的一倍并且大于64m时,会触发重写机制。
优点
1 AOF有着多种持久化策略:
2AOF文件是一个只进行追加操作的日志文件,对文件写入不需要进行seek
3 Redis可以在AOF文件变得过大时,会自动地在后台对AOF进行重写:重写后的新的AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建AOF文件的过程中,会继续将命令追加到现有的AOF文件中,即使在重写的过程中发生宕机,现有的AOF文件也不会丢失。一旦新AOF文件创建完毕,Redis就会从旧的AOF文件切换到新的AOF文见
4.AOF文件有序地保存了对数据库执行的所有写入操作。
缺点
1.对于相同的数据集来说,AOF文件要比RDB文件大。
2.根据所使用的持久化策略来说,一般AOF的速度要慢与RDB。一般情况下,每秒同步策略效果较好。不使用同步策略的情况下,AOF与RDB速度一样快。
设计模式
工厂模式,抽象工厂模式,单例模式,代理模式
JVM
什么是JVM,有什么作用?
JVM是Java虚拟机的缩写,是Java程序可以跨平台的基础。它的作用是加载Java程序,把字节码翻译成机器码交给CPU执行。
JVM的主要组成部分
- 类加载器
- 运行时数据区
- 执行引擎
- 本地库接口
工作流程
首先程序在执行之前先要把 Java 代码(.java)转换成字节码(.class),JVM 通过类加载器(ClassLoader)把字节码加载到内存中,但字节码文件是 JVM 的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine) 将字节码翻译成底层机器码,再交由 CPU 去执行,CPU 执行的过程中需要调用本地库接口(Native Interface)来完成整个程序的运行。
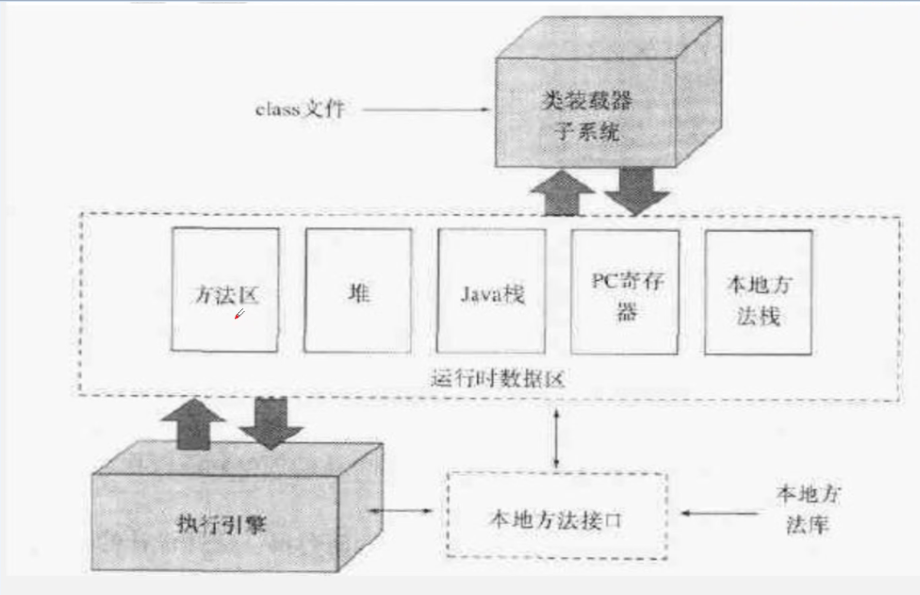
JVM内存划分
- 堆
- 本地方法栈
- JVM栈
- 本地方法区
- 程序计数器
CMS垃圾回收器
CMS是一种以获得最短停顿时间为目标的收集器,非常实用B/S系统。
CMS的优缺点
优点:CMS垃圾回收器使用多线程,标记清除垃圾。
缺点:对CPU要求敏感;无法清除浮动垃圾;垃圾回收时会产生大量空间碎片。
常见面试题
什么是跨域问题?怎么解决?
跨域问题指的是不同站点之间,使用ajax无法相互调用的问题。跨域问题是浏览器的行为,是为了保护用户信息安全,防止恶意网站窃取数据所做的限制,如果没有跨域限制就会导致信息被随意篡改和提交。
解决方案
- jsonp
- nginx请求转发,把不同站点应用配置到同一个域名下
- 服务端设置运行跨域访问,如果使用的是Spring框架可通过@CrossOrigin注解配置跨域
算法
二分查找
有序数组,每次从中间比较。
斐波那契数列
return Fib(n-1)+Fib(n-2);
一般而言,兔子在出生两个月后,就有繁殖能力,一对兔子每个月能生出一对小兔子来。如果所有兔子都不死,那么一年以后可以繁殖多少对兔子?请使用代码实现。
斐波那契数列
冒泡排序
两层循环(0-length,1-length),两个数比较
选择排序
两层循环(0-length,i+1 - length),找最小值的角标,和i交换
插入排序
把数组分为有序数组和无序数组。每一轮从无序数组中的第一个数,向有序数组中插入。
int i,j,temp;
for ( i = 1; i < a.length; i++) {
temp = a[i];
for( j = i-1; j>=0 && a[j]>temp ;j--)
a[j+1] = a[j];
a[j+1] = temp;
}快排
选择一个基准值,小于他的放左边,大于他的放右边。
public static void quickSort(int[] a,int left,int right) { if (a == null) { return ; } if(left>=right) return ; int start = left; int end = right; int flag = left; while(left<right) { while((left<right) && (a[right]>=a[flag]) ) { right--; } if(a[right]<a[flag]) { int temp = a[right]; a[right] = a[flag]; a[flag] = temp; flag = right; } while((left<right) && (a[left]<=a[flag])) { left++; } if(a[left] > a[flag]) { int temp = a[left]; a[left] = a[flag]; a[flag] = temp; flag = left; } } quickSort(a, start, left-1); quickSort(a, left+1, end); }- 堆排序
public static void heapSort(int[] a)
{
if(a==null) return ;
int length = a.length;
while(length>1)
{
for(int i = length/2;i>=1;i--)
{
if(a[i-1] < a[2*i-1] ) //和左孩子比较
{
int temp = a[i-1];
a[i-1] = a[2*i-1];
a[2*i-1] = temp;
}
if((2*i+1<=length) && (a[i-1] < a[2*i-1+1])) //和右孩子比较
{
int temp = a[i-1];
a[i-1] = a[2*i];
a[2*i] = temp;
}
}
int t = a[0];
a[0] = a[length-1];
a[length-1] = t;
length--;
}
}观察者模式
定义对象间一对多的关系,当一个对象的状态改变时,所有依赖于它的对象都会得到通知自动更新。
适配器模式
将一类的接口转换为客户需要的另外一个接口,适配器模式可以让原本接口不兼容导致不能一起工作的类一起工作。
树的遍历
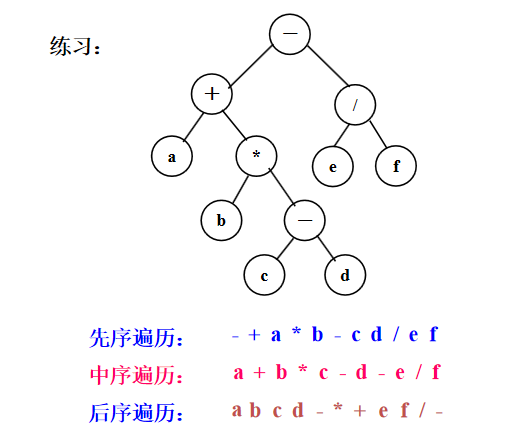
abcdefghk 根左右
bdcaehgkf 左根右
dcbhkgfea 左右根
class BitTree
{
int data;
BitTree lchild;
BitTree rchild;
public BitTree(int data)
{
this.data = data;
lchild = rchild = null;
}
//创建二叉树
public static BitTree createBitTree1(Scanner reader)
{
BitTree root = null;
int m=reader.nextInt();
if(m>=0)
{
root = new BitTree(m);
root.lchild = createBitTree1(reader);
root.rchild = createBitTree1(reader);
}
return root;
}
//递归遍历
public static void print(BitTree root)
{
if(root == null) return;
//前序
System.out.println(root.data);
print(root.lchild);
//中序
//System.out.println(root.data);
print(root.rchild);
//后序
//System.out.println(root.data);
}
//非递归遍历
//前序
public static void printByPre(BitTree root)
{
if(root==null) return;
Stack<BitTree> stack = new Stack<BitTree>();
stack.push(root);
while(!stack.isEmpty())
{
root = stack.pop();
System.out.println(root.data);
if(root.lchild != null) stack.push(root.lchild);
if(root.rchild != null) stack.push(root.rchild);
}
}
//中序
public static void printByMid(BitTree root)
{
if(root == null) return;
Stack<BitTree> stack = new Stack<BitTree>();
stack.push(root);
while(!stack.isEmpty())
{
root = stack.pop();
if(root==null) continue;
if ((root.lchild == null && root.rchild == null) || (!stack.isEmpty() && stack.peek()==root.rchild)) {
System.out.println(root.data);
continue;
}
stack.push(root.rchild);
stack.push(root);
if(root.lchild !=null) stack.push(root.lchild);
}
}
//后序
public static void printByBack(BitTree root)
{
if(root ==null) return;
Stack<BitTree> stack = new Stack<BitTree>();
stack.push(root);
BitTree visited = null;
while(!stack.isEmpty())
{
root = stack.pop();
if(root == null) continue;
if((root.lchild==null && root.rchild == null) || (root.lchild == visited && root.rchild == null)
|| (root.rchild == visited))
{
System.out.println(root.data);
visited = root;
continue;
}
stack.push(root);
if(root.rchild != null) stack.push(root.rchild);
if(root.lchild != null) stack.push(root.lchild);
}
}
}链表
class Node
{
int data;
Node next;
public Node()
{
}
public Node(int m)
{
this.data = m;
this.next = null;
}
//头插
public static Node createNodeByHead(Scanner reader)
{
Node head = null;
int m = reader.nextInt();
while(m>=0)
{
Node p = new Node(m);
p.next = head;
head = p;
m = reader.nextInt();
}
return head;
}
//尾插
public static Node createNodeByTail(Scanner reader)
{
Node head = null;
Node tail = null;
int m = reader.nextInt();
while(m>=0)
{
Node p = new Node(m);
if(head==null) head=tail=p;
else
{
tail.next = p;
tail = p;
}
m = reader.nextInt();
}
return head;
}
}


